
Nothing sounds more futuristic than artificial intelligence (AI). Our predictions about the future of AI are largely shaped by science fiction. Go to any conference, skim any WIRED article, peruse any gallery of stock images depicting AI*, and you can’t help but imagine AI as a disembodied cyberbabe (as in Spike Jonze’s Her), a Tin Man (who just wanted a heart!) gone rogue (as in the Terminator), or, my personal favorite, a brain out-of-the-vat-like-a-fish-out-of-water-and-into-some-non-brain-appropriate-space-like-a-robot-hand-or-an-android-intestine (as in Krang in the Ninja Turtles).


The truth is, AI looks more like this:

Of course, it takes domain expertise to picture just what kind of embodied AI product such formal mathematical equations would create. Visual art, argued Gene Kogan, a cosmopolitan coder-artist, may just be the best vehicle we have to enable a broader public to develop intuitions of how machine learning algorithms transform old inputs into new outputs.
One of Gene Kogan‘s beautiful machine learning recreations.
What’s important is that our imagining AI as superintelligent robots — robots that process and navigate the world with a similar-but-not-similar-enough minds, lacking values and the suffering that results from being social — precludes us from asking the most interesting philosophical and ethical questions that arise when we shift our perspective and think about AI as trained on past data and working inside feedback loops contingent upon prior actions.
Left unchecked, AI may actually be an inherently conservative technology. It functions like a time warp, capturing trends in human behavior from our near past and projecting them into our near future. As Alistair Croll recently argued, “just because [something was] correct in the past doesn’t make it right for the future.”
Our Future as Recent Past: The Case of Word Embeddings
In graduate school, I frequently had a jarring experience when I came home to visit my parents. I was in my late twenties, and was proud of the progress I’d made evolving into a more calm, confident, and grounded me. But the minute I stepped through my parents’ door, I was confronted with the reflection of a past version of myself. Logically, my family’s sense of my identity and personality was frozen in time: the last time they’d engaged with me on a day-to-day basis was when I was 18 and still lived at home. They’d anticipate my old habits, tiptoeing to avoid what they assumed would be a trigger for anxiety. Their behavior instilled doubt. I questioned whether the progress I assumed I’d made was just an illusion, and quickly fall back into old habits.
In fact, the discomfort arose from a time warp. I had progressed, I had grown, but my parents projected the past me onto the current me, and I regressed under the impact of their response. No man is an island. Our sense of self is determined not only by some internal beacon of identity, but also (for some, mostly) by the self we interpret ourselves to be given how others treat us and perceive us. Each interaction nudges us in some direction, which can be a regression back to the past or a progression into a collective future.
AI systems have the potential to create this same effect at scale across society. The shock we feel upon learning that algorithms automating job ads show higher-paying jobs to men rather than women, or recidivism-prediction tools place African-American males at higher risk than other races and classes, results from recapitulating issues we assume society has already advanced beyond. Sometimes we have progressed, and the tools are simply reflections for the real-world prejudices of yore; sometimes we haven’t progressed as much as we’d like to pretend, and the tools are barometers for the hard work required to make the world a world we want to live in.
Consider this research about a popular natural language processing (NLP) technique called word embeddings by Bolukbasi and others in 2016.**
The essence of NLP is to to make human talk (grey, messy, laden with doubts and nuances and sarcasm and local dialectics and….) more like machine talk (black and white 1s and 0s). Historically, NLP practitioners did this by breaking down language into different parts and using those parts as entities in a system.
Naturally, this didn’t get us as far as we’d hoped. With the rise of big data in the 2000s, many in the NLP community adopted a new approach based on statistics. Instead of teasing out structure in language with trees, they used massive processing power to find repeated patterns across millions of example sentences. If two words (or three, or four, or the general case, n) appeared multiple times in many different sentences, programmers assumed the statistical significance of that word pair conferred semantic meaning. Progress was made, but this n-gram technique failed to capture long-term, hierarchical relationships in language: how words at the end of a sentence or paragraph inflect the meaning of the beginning, how context inflects meaning, how other nuances make language different from a series of transactions at a retail store.
Word embeddings, made popular in 2013 with a Google technique called word2vec, use a vector, a string of numbers pointing in some direction in an N-dimensional space***, to capture (more of) the nuances of contextual and long-term dependencies (the 6589th number in the string, inflected in the 713th dimension, captures the potential relationship between a dangling participle and the subject of the sentence with 69% accuracy). This conceptual shift is powerful: instead of forcing simplifying assumptions onto language, imposing arbitrary structure to make language digestible for computers, these embedding techniques accept that meaning is complex, and therefore must be processed with techniques that can harness and harvest that complexity. The embeddings make mathematical mappings that capture latent relationships our measly human minds may not be able to see. This has lead to breakthroughs in NLP, like the ability to automatically summarize text (albeit in a pretty rudimentary way…) or improve translation systems.
With great power, of course, comes great responsibility. To capture more of the inherent complexity in language, these new systems require lots of training data, enough to capture patterns versus one-off anomalies. We have that data, and it dates back into our recent - and not so recent - past. And as we excavate enough data to unlock the power of hierarchical and linked relationships, we can’t help but confront the lapsed values of our past.
Indeed, one powerful property of word embeddings is their ability to perform algebra that represents analogies. For example, if we input: “man is to woman as king is to X?” the computer will output: “queen!” Using embedding techniques, this operation is conducted by using a vector - a string of numbers mapped in space - as a proxy for analogy: if two vectors have the same length and point in the same direction, we consider the words at each pole semantically related.
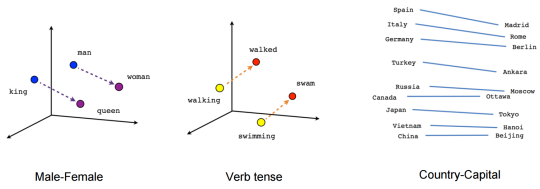
Now, Bolukbasi and fellow researchers dug into this technique and found some relatively disturbing results.

It’s important we remember that the AI systems themselves are neutral, not evil. They’re just going through the time warp, capturing and reflecting past beliefs we had in our society that leave traces in our language. The problem is, if we are unreflective and only gauge the quality of our systems based on the accuracy of their output, we may create really accurate but really conservative or racist systems (remember Microsoft Tay?). We need to take a proactive stance to make sure we don’t regress back to old patterns we thought we’ve moved past. Our psychology is pliable, and it’s very easy for our identities to adapt to the reflections we’re confronted with in the digital and physical world.
Bolukbasi and his co-authors took an interesting, proactive approach to debiasing their system, which involved mapping the words associated with gender in two dimensions, where the X axis represented gender (girls to the left and boys to the right). Words associated with gender but that don’t stir sensitivities in society were mapped under the X axis (e.g., girl : sister :: boy : brother). Words that do stir sensitivities (e.g., girl : tanning :: boy : firepower) were forced to collapse down to the Y axis, stripping them of any gender association.

Their efforts show what mindfulness may look like in the context of algorithmic design. Just as we can’t run away from the inevitable thoughts and habits in our mind, given that they arise from our past experience, the stuff that shapes our minds to make us who we are, so too we can’t run away from the past actions of our selves and our society. It doesn’t help our collective society to blame the technology as evil, just as it doesn’t help any individual to repress negative emotions. We are empowered when we acknowledge them for what they are, and proactively take steps to silence and harness them so they don’t keep perpetuating in the future. This level of awareness is required for us to make sure AI is actually a progressive, futuristic technology, not one that traps us in the unfortunate patterns of our collective past.
Conclusion
This is one narrow example of the ethical and epistemological issues created by AI. In a future blog post in this series, I’ll explore how reinforcement learning frameworks - in particular contextual bandit algorithms - shape and constrain the data collected to train their systems, often in a way that mirrors the choices and constraints we face when we make decisions in real life.
*Len D’Avolio, Founder CEO of healthcare machine learning startup Cyft, curates a Twitter feed of the worst-ever AI marketing images every Friday. Total gems.
**This is one of many research papers on the topic. FAT ML is a growing community focused on fairness, accountability, and transparency in machine learning. the brilliant Joanna Bryson has written articles about bias in NLP systems. Cynthia Dwork and Toni Pitassi are focusing more on bias (though still do great work on differential privacy). Blaise Aguera y Arcas’ research group at Google thinks deeply about ethics and policy and recently published an article debunking the use of physiognomy to predict criminality. My colleague Tyler Schnoebelen recently gave a talk on ethical AI product design at Wrangle. The list goes on.
***My former colleague Hilary Mason loved thinking about the different ways we imagine spaces of 5 dimensions or greater.
The featured image is from Swedish film director Ingmar Bergman‘s Wild Strawberries (1957). Bergman’s films are more like philosophical essays than Hollywood thrillers. He uses medium, with its ineluctable flow, its ineluctable passage of time, to ponder the deepest questions of meaning and existence. A clock without hands, at least if we’re able to notice it, as our mind’s eye likely fills in the semantic gaps with the regularity of practice and habit. The eyes below betokening what we see and do not see. Bergman died June 30, 2007 the same day as Michelangelo Antonioni, his Italian counterpart. For me, the coincidence was as meaningful as that of the death of John Adams and Thomas Jefferson on July 4, 1826.
