Nothing sounds more futuristic than artificial intelligence (AI). Our predictions about the future of AI are largely shaped by science fiction. Go to any conference, skim any WIRED article, peruse any gallery of stock images depicting AI*, and you can’t help but imagine AI as a disembodied cyberbabe (as in Spike Jonze’s Her), a Tin Man (who just wanted a heart!) gone rogue (as in the Terminator), or, my personal favorite, a brain out-of-the-vat-like-a-fish-out-of-water-and-into-some-non-brain-appropriate-space-like-a-robot-hand-or-an-android-intestine (as in Krang in the Ninja Turtles).
A legit AI marketing photo!Krang should be the AI mascot, not the Terminator!
Of course, it takes domain expertise to picture just what kind of embodied AI product such formal mathematical equations would create. Visual art, argued Gene Kogan, a cosmopolitan coder-artist, may just be the best vehicle we have to enable a broader public to develop intuitions of how machine learning algorithms transform old inputs into new outputs.
One of Gene Kogan‘s beautiful machine learning recreations.
What’s important is that our imagining AI as superintelligent robots — robots that process and navigate the world with a similar-but-not-similar-enough minds, lacking values and the suffering that results from being social — precludes us from asking the most interesting philosophical and ethical questions that arise when we shift our perspective and think about AI as trained on past data and working inside feedback loops contingent upon prior actions.
Left unchecked, AI may actually be an inherently conservative technology. It functions like a time warp, capturing trends in human behavior from our near past and projecting them into our near future. As Alistair Croll recently argued, “just because [something was] correct in the past doesn’t make it right for the future.”
Our Future as Recent Past: The Case of Word Embeddings
In graduate school, I frequently had a jarring experience when I came home to visit my parents. I was in my late twenties, and was proud of the progress I’d made evolving into a more calm, confident, and grounded me. But the minute I stepped through my parents’ door, I was confronted with the reflection of a past version of myself. Logically, my family’s sense of my identity and personality was frozen in time: the last time they’d engaged with me on a day-to-day basis was when I was 18 and still lived at home. They’d anticipate my old habits, tiptoeing to avoid what they assumed would be a trigger for anxiety. Their behavior instilled doubt. I questioned whether the progress I assumed I’d made was just an illusion, and quickly fall back into old habits.
In fact, the discomfort arose from a time warp. I had progressed, I had grown, but my parents projected the past me onto the current me, and I regressed under the impact of their response. No man is an island. Our sense of self is determined not only by some internal beacon of identity, but also (for some, mostly) by the self we interpret ourselves to be given how others treat us and perceive us. Each interaction nudges us in some direction, which can be a regression back to the past or a progression into a collective future.
AI systems have the potential to create this same effect at scale across society. The shock we feel upon learning that algorithms automating job ads show higher-paying jobs to men rather than women, or recidivism-prediction tools place African-American males at higher risk than other races and classes, results from recapitulating issues we assume society has already advanced beyond. Sometimes we have progressed, and the tools are simply reflections for the real-world prejudices of yore; sometimes we haven’t progressed as much as we’d like to pretend, and the tools are barometers for the hard work required to make the world a world we want to live in.
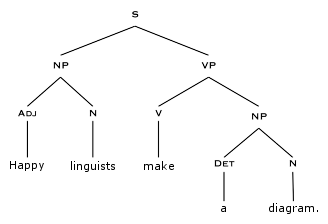
The essence of NLP is to to make human talk (grey, messy, laden with doubts and nuances and sarcasm and local dialectics and….) more like machine talk (black and white 1s and 0s). Historically, NLP practitioners did this by breaking down language into different parts and using those parts as entities in a system.
Tree graphs parsing language into parts, inspired by linguist Noam Chomsky.
Naturally, this didn’t get us as far as we’d hoped. With the rise of big data in the 2000s, many in the NLP community adopted a new approach based on statistics. Instead of teasing out structure in language with trees, they used massive processing power to find repeated patterns across millions of example sentences. If two words (or three, or four, or the general case, n) appeared multiple times in many different sentences, programmers assumed the statistical significance of that word pair conferred semantic meaning. Progress was made, but this n-gram technique failed to capture long-term, hierarchical relationships in language: how words at the end of a sentence or paragraph inflect the meaning of the beginning, how context inflects meaning, how other nuances make language different from a series of transactions at a retail store.
Word embeddings, made popular in 2013 with a Google technique called word2vec, use a vector, a string of numbers pointing in some direction in an N-dimensional space***, to capture (more of) the nuances of contextual and long-term dependencies (the 6589th number in the string, inflected in the 713th dimension, captures the potential relationship between a dangling participle and the subject of the sentence with 69% accuracy). This conceptual shift is powerful: instead of forcing simplifying assumptions onto language, imposing arbitrary structure to make language digestible for computers, these embedding techniques accept that meaning is complex, and therefore must be processed with techniques that can harness and harvest that complexity. The embeddings make mathematical mappings that capture latent relationships our measly human minds may not be able to see. This has lead to breakthroughs in NLP, like the ability to automatically summarize text (albeit in a pretty rudimentary way…) or improve translation systems.
With great power, of course, comes great responsibility. To capture more of the inherent complexity in language, these new systems require lots of training data, enough to capture patterns versus one-off anomalies. We have that data, and it dates back into our recent - and not so recent - past. And as we excavate enough data to unlock the power of hierarchical and linked relationships, we can’t help but confront the lapsed values of our past.
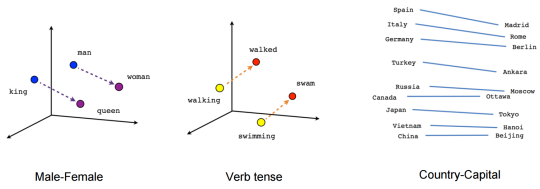
Indeed, one powerful property of word embeddings is their ability to perform algebra that represents analogies. For example, if we input: “man is to woman as king is to X?” the computer will output: “queen!” Using embedding techniques, this operation is conducted by using a vector - a string of numbers mapped in space - as a proxy for analogy: if two vectors have the same length and point in the same direction, we consider the words at each pole semantically related.
Embeddings use vectors as a proxy for semantics and syntax.
Now, Bolukbasi and fellow researchers dug into this technique and found some relatively disturbing results.
It’s important we remember that the AI systems themselves are neutral, not evil. They’re just going through the time warp, capturing and reflecting past beliefs we had in our society that leave traces in our language. The problem is, if we are unreflective and only gauge the quality of our systems based on the accuracy of their output, we may create really accurate but really conservative or racist systems (remember Microsoft Tay?). We need to take a proactive stance to make sure we don’t regress back to old patterns we thought we’ve moved past. Our psychology is pliable, and it’s very easy for our identities to adapt to the reflections we’re confronted with in the digital and physical world.
Bolukbasi and his co-authors took an interesting, proactive approach to debiasing their system, which involved mapping the words associated with gender in two dimensions, where the X axis represented gender (girls to the left and boys to the right). Words associated with gender but that don’t stir sensitivities in society were mapped under the X axis (e.g., girl : sister :: boy : brother). Words that do stir sensitivities (e.g., girl : tanning :: boy : firepower) were forced to collapse down to the Y axis, stripping them of any gender association.
Their efforts show what mindfulness may look like in the context of algorithmic design. Just as we can’t run away from the inevitable thoughts and habits in our mind, given that they arise from our past experience, the stuff that shapes our minds to make us who we are, so too we can’t run away from the past actions of our selves and our society. It doesn’t help our collective society to blame the technology as evil, just as it doesn’t help any individual to repress negative emotions. We are empowered when we acknowledge them for what they are, and proactively take steps to silence and harness them so they don’t keep perpetuating in the future. This level of awareness is required for us to make sure AI is actually a progressive, futuristic technology, not one that traps us in the unfortunate patterns of our collective past.
Conclusion
This is one narrow example of the ethical and epistemological issues created by AI. In a future blog post in this series, I’ll explore how reinforcement learning frameworks - in particular contextual bandit algorithms - shape and constrain the data collected to train their systems, often in a way that mirrors the choices and constraints we face when we make decisions in real life.
*Len D’Avolio, Founder CEO of healthcare machine learning startup Cyft, curates a Twitter feed of the worst-ever AI marketing images every Friday. Total gems.
***My former colleague Hilary Mason loved thinking about the different ways we imagine spaces of 5 dimensions or greater.
The featured image is from Swedish film director Ingmar Bergman‘s Wild Strawberries (1957). Bergman’s films are more like philosophical essays than Hollywood thrillers. He uses medium, with its ineluctable flow, its ineluctable passage of time, to ponder the deepest questions of meaning and existence. A clock without hands, at least if we’re able to notice it, as our mind’s eye likely fills in the semantic gaps with the regularity of practice and habit. The eyes below betokening what we see and do not see. Bergman died June 30, 2007 the same day as Michelangelo Antonioni, his Italian counterpart. For me, the coincidence was as meaningful as that of the death of John Adams and Thomas Jefferson on July 4, 1826.
I spent the last few days in Paris at Transform.AI, a European conference designed for c-level executives managed and moderated by my dear friend Joanna Gordon. This type of high-quality conference approaching artificial intelligence (AI) at the executive level is sorely needed. While there’s no lack of high-quality technical discussion at research conferences like ICML and NIPS, or even part-technical, part-application, part-venture conferences like O’Reilly AI, ReWork, or the Future Labs AI Summit (which my friends at ffVC did a wonderful job producing), most c-level executives still actively seek to cut through the hype and understand AI deeply and clearly enough to invest in tools, people, and process changes with confidence. Confidence, of course, is not certainty. And with technology changing at an ever faster clip, the task of running the show while transforming the show to keep pace with the near future is not for the faint of heart.
Transform.AI brought together enterprise and startup CEOs, economists, technologists, venture capitalists, and journalists. We discussed the myths and realities of the economic impact of AI, enterprise applications of AI, the ethical questions surrounding AI, and the state of what’s possible in the field. Here are some highlights.*
The Productivity Paradox: New Measures for Economic Value
The productivity paradox is the term Ryan Avent of the Economist uses to describe the fact that, while we worry about a near-future society where robots automate away both blue-collar and white-collar work, the present economy “does not feel like one undergoing a technology-driven productivity boom.” Indeed, as economists noted at Transform.AI, in developed countries like the US, job growth is up and “productivity has slowed to a crawl.” In his Medium post, Avent shows how economic progress is not a linear substitution equation: automation doesn’t impact growth and GDP by simply substituting the cost of labor with the cost of capital (i.e., replacing a full-time equivalent employee with an intelligent robot) despite our — likely fear-inspired — proclivities to reduce automation to simple swaps of robot for human. Instead, Avent argues that “the digital revolution is partly responsible for low labor costs” (by opening supply for cheap labor via outsourcing or just communication), that “low labour costs discourage investments in labour-saving technology, potentially reducing productivity growth,” and that benefiting from the potential of automation from new technologies like AI costs far more than just capital equipment, as it takes a lot of investment to get people, processes, and underlying technological infrastructure in place to actually use new tools effectively. There are reasons why IBM, McKinsey, Accenture, Salesforce, and Oracle make a lot of money off of “digital transformation” consulting practices.
The takeaway is that innovation and the economic impact of innovation move in syncopation, not tandem. The consequence of this syncopation is the plight of shortsightedness, the “I’ll believe it when I see it” logic that we also see from skeptics of climate change who refuse to open their imagination to any consequences beyond their local experience. The second consequence is the overly simplistic rhetoric of technocratic Futurism, which is also hard to swallow because it does not adequately account for the subtleties of human and corporate psychology that are the cornerstones of adoption. One conference attendee, the CEO of a computer vision startup automating radiology, commented that his firm can produce feature advances in their product 50 times faster than the market will be ready to use them. And this lag results not only from the time and money required for hospitals to modify their processes to accommodate machine learning tools, but also the ethical and psychological hurdles that need to be overcome to both accommodate less-than-certain results and accept a system that cannot explain why it arrived at its results.
In addition, everyone seemed to agree that the metrics used to account for growth, GDP, and other macroeconomic factors in the 20th-century may not be apt for the networked, platform-driven, AI-enabled economy of the 21st. For example, the value search tools like Google have on the economy far supersedes the advertising spends accounted for by company revenues. Years ago, when I was just beginning my career, my friend and mentor Geoffrey Moore advised me that traditional information-based consulting firms were effectively obsolete in the age of ready-at-hand information (the new problem being the need to erect virtual dams - using natural language processing, recommendation, and fact-checking algorithms - that can channel and curb the flood of available information). Many AI tools effectively concatenate past human capital - the expertise and value of a skilled-services work - into a present-day super-human laborer, a laborer who is the emergent whole (so more than the sum of its parts) of all past human work (well, just about all - let’s say normalized across some distribution). This fusion of man and machine**, of man’s past actions distilled into a machine, a machine that then works together with present and future employees to ever improve its capabilities, forces us to revisit what were once clean delineations between people, IP, assets, and information systems, the engines of corporations.
Accenture calls the category of new job opportunities AI will unlock The Missing Middle. Chief Technology and Innovation Officer Paul Daugherty and others have recently published an MIT Sloan article that classifies workers in the new AI economy as “trainers” (who train AI systems, curating input data and giving them their personality), “explainers” (who speak math and speak human, and serve as liaisons between the business and technology teams), and “sustainers” (who maintain algorithmic performance and ensure systems are deployed ethically). Those categories are sound. Time will tell how many new jobs they create.
Unrealistic Expectations and Realistic Starting Points
Everyone seems acutely aware of the fact that AI is in a hype cycle. And yet everyone still trusts AI is the next big thing. They missed the internet. They were too late for digital. They’re determined not to be too late for AI.
The panacea would be like the chip Keanu Reeves uses in the Matrix, the preprogrammed super-intelligent system you just plug into the equivalent of a corporate brain and boom, black belt karate-style marketing, anomaly detection, recommender systems, knowledge management, preemptive HR policies, compliance automation, smarter legal research, optimized supply chains, etc…
If only it were that easy.
While everyone knows we are in a hype cycle, technologists still say that one of the key issues data scientists and startups face today are unrealistic expectations from executives. AI systems still work best when they solve narrow, vertical-specific problems (which also means startups have the best chance of succeeding when they adopt a vertical strategy, as Bradford Cross eloquently argued last week). And, trained on data and statistics, AI systems output probabilities, not certainties. Electronic Discovery (i.e., the use of technology to automatically classify documents as relevant or not for a particular litigation matter) adoption over the past 20 years has a lot to teach us about the psychological hurdles to adoption of machine learning for use cases like auditing, compliance, driving, or accounting. People expect certainty, even if they are deluding themselves about their own propensities for error.*** We have a lot of work to disabuse people of their own foibles and fallacies before we can enable them to trust probabilistic systems and partner with them comfortably. That’s why so many advocates of self-driving cars have to spend time educating people about the fatality rates of human drivers. We hold machines to different standards of performance and certainty because we overestimate our own powers of reasoning. Amos Tversky and Daniel Kahneman are must reads for this new generation (Michael Lewis’s Undoing Project is a good place to start). We expect machines to explain why they arrived at a given output because we fool ourselves, often by retrospective narration, that we are principled in making our own decisions, and we anthropormophize our tools into having little robot consciousnesses. It’s an exciting time for cognitive psychology, as it will be critical for any future economic growth that can arise from AI.
It doesn’t seem possible not to be in favor of responsible AI. Everyone seems to be starting to take this seriously. Conference attendees seemed to agree that there needs to be much more discourse between technologists, executives, and policy makers so that regulations like the European GPDR don’t stymy progress, innovation, and growth. The issues are enormously subtle, and for many we’re only at the point of being able to recognize that there are issues rather than provide concrete answers that can guide pragmatic action. For example, people love to ponder liability and IP, analytically teasing apart different loca of agency: Google or Amazon who offered the opensource library like Tensorflow, the organization or individual upon whose data a tool was trained, the data scientist who wrote the code for the algorithm, the engineer who wrote the code to harden and scale the solution, the buyer of the tool who signed the contract to use it and promised to update the code regularly (assuming it’s not on the cloud, in which case that’s the provider again), the user of the tool, the person whose life was impacted by consuming the output. From what I’ve seen, so far we’re at the stage where we’re transposing an ML pipeline into a framework to assign liability. We can make lists and ask questions, but that’s about as far as we get. The rubber will meet the road when these pipelines hit up against existing concepts to think through tort and liability. Solon Barocas and the wonderful team at Upturn are at the vanguard of doing this kind of work well.
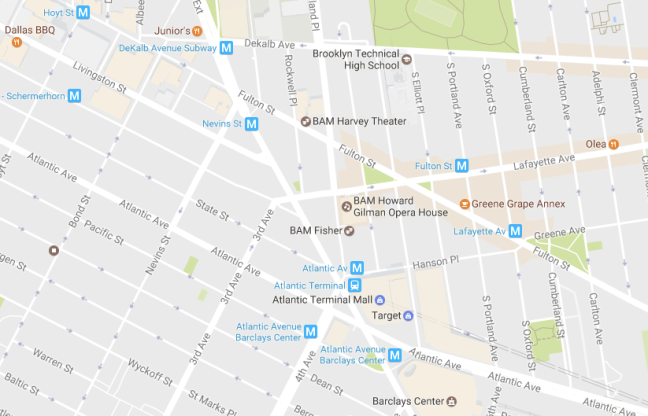
Finally, I moderated a panel with a few organizations who are already well underway with their AI innovation efforts. Here we are (we weren’t as miserable as we look!):
Journeys Taken; Lessons Learned Panelists at Transform.AI
The lesson I learned synthesizing the comments from the panelists is salient: customers and clients drive successful AI adoption efforts. I’ve written about the complex balance between innovation and application on this blog, having seen multiple failed efforts to apply a new technology just because it was possible. A lawyer on our panel discussed how, since the 2009 recession, clients simply won’t pay high hourly rates for services when they can get the same job done at a fraction of the cost at KPMG, PWC, or a technology vendor. Firms have no choice but to change how they work and price matters, and AI happens to be the tool that can parse text and crystallize legal know how. In the travel vertical, efforts to reach customers on traditional channels just don’t cut it in the age where the Millenials live on digital platforms like Facebook Messenger. And if a chat bot is the highest value channel, then an organization has to learn how to interface with chat bots. This fueled a top down initiative to start investing heavily in AI tools and talent.
Exactly where to put an AI or data science team to strike the right balance between promoting autonomy, minimizing disruption, and optimizing return varies per organization. Daniel Tunkelang presented his thoughts on the subject at the Fast Forward Labs Data Leadership conference this time last year.
Technology Alone is Not Enough: The End of The Two Cultures
I remember sitting in Pigott Hall on Stanford Campus in 2011. It was a Wednesday afternoon, and Michel Serres, a friend, mentor, and âme soeur,**** was giving one of his weekly lectures, which, as so few pull off well, elegantly packaged some insight from the history of mathematics in a masterful narrative frame.***** He bid us note the layout of Stanford campus, with the humanities in the old quad and the engineering school on the new quad. The very topography, he showed, was testimony to what C.P. Snow called The Two Cultures, the fault line between the hard sciences and the humanities that continues to widen in our STEM-obsessed, utilitarian world. It certainly doesn’t help that tuitions are so ludicrously high that it feels irresponsible to study a subject, like philosophy, art history, or literature, that doesn’t guarantee job stability or economic return. That said, Christian Madsbjerg of ReD Associates has recently shown in Sensemaking that liberal arts majors, at least those fortunate enough to enter management positions, end up having much higher salaries than most engineers in the long run. (I recognize the unfathomable salaries of top machine learning researchers likely undercuts this, but it’s still worth noting).
Can, should, and will the stark divide between the two cultures last?
Transform.AI attendees exhibited few points in favour of cultivating a new fusion between the humanities and the sciences/technology.
First, with the emerging interest paid to the ethics of AI, it may not be feasible for non-technologists to claim ignorance or allergic reactions to any mathematical and formal thinking as an excuse not to contribute rigorously to the debate. If people care about these issues, it is their moral obligation to make the effort to get up to speed in a reasonable way. This doesn’t mean everyone becomes literate in Python or active on scikit-learn. It just means having enough patience to understand the concepts behind the math, as that’s all these systems are.
Next, as I’ve argued before, for the many of us who are not coders or technologists, having the mental flexibility, creativity, and critical thinking skills awarded from a strong (and they’re not all strong…) humanities education will be all the more valuable as more routine, white-collar jobs gradually get automated. Everyone seems to think studying the arts and reading books will be cool again. And within Accenture’s triptych of new jobs and roles, there will be a large role for people versed in ethnography, ethics, and philosophy to define the ethical protocol of using these systems in a way that accords with corporate values.
Finally, the attendees’ reaction to a demo by Soul Machines, a New Zealand-based startup taking conversational AI to a whole new uncanny level, channeled the ghost of Steve Jobs: “Technology alone is not enough—it’s technology married with liberal arts, married with the humanities, that yields us the results that make our heart sing.” Attendees paid mixed attention to most of the sessions, always pulled back to the dopamine hit available from a quick look at their cell phones. But they sat riveted (some using their phones to record the demo) when Soul Machines CEO Mark Sagar, a two-time Academy Award winner for his work on films like Avatar, demoed a virtual baby who exhibits emotional responses to environmental stimulai and showed a video clip of Nadia, the “terrifying human” National Disability Insurance Scheme (NDIS) virtual agent enlivened by Cate Blanchett. The work is really something, and it confirmed that the real magic in AI arises not from the mysteriousness of the math, but the creative impulse to understand ourselves, our minds, and our emotions by creating avatars and replicas with which we’re excited to engage.
My congratulations to Joanna Gordon for all her hard work. I look forward to next year’s event!
*Most specific names and references are omitted to respect the protocol of the Chatham House Rule.
**See J.D. Licklider’s canonical 1960 essay Man-Computer Symbiosis. Hat tip to Steve Lohr from the New York Times for introducing me to this.
***Stay tuned next week for a post devoted entirely to the lessons we can learn from the adoption of electronic discovery technologies over the past two decades.
****Reflecting on the importance of the lessons Michel Serres taught me is literally bringing tears to my eyes. Michel taught me how to write. He taught me why we write and how to find inspiration from, on the one hand, love and desire, and, on the other hand, fastidious discipline and habit. Tous les matins - every morning. He listed the greats, from Leibniz to Honoré de Balzac to Leo Tolstoy to Thomas Mann to William Faulker to himself, who achieved what they did by adopting daily practices. Serres popularized many of the great ideas from the history of mathematics. He was criticized by the more erudite of the French Académie, but always maintained his southern soul. He is a marvel, and an incredibly clear and creative thinker.
*****Serres gave one of the most influential lectures I’ve ever heard in his Wednesday afternoon seminars. He narrated the connection between social contract theory and the tragic form in the 17th century with a compact, clever anecdote of a WW II sailor and documentary film maker (pseudo-autobiographical) who happens to film a fight that escalates from a small conflict between two people into an all out brawl in a bar. When making his film, in his illustrative allegory, he plays the tape in reverse, effectively going from the state of nature - a war of all against all - to two representatives of a culture who carry the weight and brunt of war - the birth of tragedy. It was masterful.
Last week, I attended the C2 conference in Montréal, which featured an AI Forum coordinated by Element AI.* Two friends from Google, Hugo LaRochelle and Blaise Agüera y Arcas, led workshops about the societal (Hugo) and ethical (Blaise) implications of artificial intelligence (AI). In both sessions, participants expressed discomfort with allowing machines to automate decisions, like what advertisement to show to a consumer at what time, whether a job candidate should pass to the interview stage, whether a power grid requires maintenance, or whether someone is likely to be a criminal.** While each example is problematic in its own way, a common response to the increasing ubiquity of algorithms is to demand a “right to explanation,” as the EU recently memorialized in the General Data Protection Regulation slated to take effect in 2018. Algorithmic explainability/interpretability is currently an active area of research (my former colleagues at Fast Forward Labs will publish a report on the topic soon and members of Geoff Hinton’s lab in Toronto are actively researching it). While attempts to make sense of nonlinear functions are fascinating, I agree with Peter Sweeney that we’re making a category mistake by demanding explanations from algorithms in the first place: the statistical outputs of machine learning systems produce new observations, not explanations. I’ll side here with my namesake, David Hume, and say we need to be careful not to fall into the ever-present trap of mistaking correlation for cause.
One reason why people demand a right to explanation is that they believe that knowing why will grant us more control over outcome. For example, if we know that someone was denied a mortgage because of their race, we can intervene and correct for this prejudice. A deeper reason for the discomfort stems from the fact that people tend to falsely attribute consciousness to algorithms, applying standards for accountability that we would apply to ourselves as conscious beings whose actions are motivated by a causal intention. (LOL***)
Now, I agree with Noah Yuval Harari that we need to frame our understanding of AI as intelligence decoupled from consciousness. I think understanding AI this way will be more productive for society and lead to richer and cleaner discussions about the implications of new technologies. But others are actively at work to formally describe consciousness in what appears to be an attempt to replicate it.
In what follows, I survey three interpretations of consciousness I happened to encounter (for the first time or recovered by analogical memory) this week. There are many more. I’m no expert here (or anywhere). I simply find the thinking interesting and worth sharing. I do believe it is imperative that we in the AI community educate the public about how the intelligence of algorithms actually works so we can collectively worry about the right things, not the wrong things.
Condillac: Analytical Empiricism
Étienne Bonnot de Condillac doesn’t have the same heavyweight reputation in the history of philosophy as Descartes (whom I think we’ve misunderstood) or Voltaire. But he wrote some pretty awesome stuff, including his Traité des Sensations, an amazing intuition pump (to use Daniel Dennett’s phrase) to explore theory of knowledge that starts with impressions of the world we take in through our senses.
Condillac wrote the Traité in 1754, and the work exhibits two common trends from the French Enlightenment:
A concerted effort to topple Descartes’s rationalist legacy, arguing that all cognition starts with sense data rather than inborn mathematical truths
A stylistic debt to Descartes’s rhetoric of analysis, where arguments are designed to conjure a first-person experience of the process of arriving at an insight, rather than presenting third-person, abstract lessons learned
The Traité starts with the assumption that we can tease out each of our senses and think about how we process them in isolation. Condillac bids the reader to imagine a statue with nothing but the sense of smell. Lacking sight, sound, and touch, the statue “has no ideas of space, shape, anything outside of herself or outside her sensations, nothing of color, sound, or taste.” She is, in my opinion incredibly sensuously, nothing but the odor of a flower we waft in front of her. She becomes it. She is totally present. Not the flower itself, but the purest experience of its scent.
As Descartes constructs a world (and God) from the incontrovertible center of the cogito, so too does Condillac construct a world from this initial pure scent of rose. After the rose, he wafts a different flower - a jasmine - in front of the statue. Each sensation is accompanied by a feeling of like or dislike, of wanting more or wanting less. The statue begins to develop the faculties of comparison and contrast, the faculty of memory with faint impressions remaining after one flower is replaced by another, the ability to suffer in feeling a lack of something she has come to desire. She appreciates time as an index of change from one sensation to the next. She learns surprise as a break from the monotony of repetition. Condillac continues this process, adding complexity with each iteration, like the escalating tension Shostakovich builds variation after variation in the Allegretto of the Leningrad Symphony.
True consciousness, for Condillac, begins with touch. When she touches an object that is not her body, the sensation is unilateral: she notes the impenetrability and resistance of solid things, that she cannot just pass through them like a ghost or a scent in the air. But when she touches her own body, the sensation is bilateral, reflexive: she touches and is touched by. C’est moi, the first notion of self-awareness, is embodied. It is not a reflexive mental act that cannot take place unless there is an actor to utter it. It is the strangeness of touching and being touched all at once. The first separation between self and world. Consciousness as fall from grace.
It’s valuable to read Enlightenment philosophers like Condillac because they show attempts made more than 200 years ago to understand a consciousness entirely different from our own, or rather, to use a consciousness different from our own as a device to better understand ourselves. The narrative tricks of the Enlightenment disguised analytical reduction (i.e., focus only on smell in absence of its synesthetic entanglement with sound and sight) as world building, turning simplicity into an anchor to build a systematic understanding of some topic (Hobbes’s and Rousseau’s states of nature and social contract theories use the same narrative schema). Twentieth-century continental philosophers after Husserl and Heidegger preferred to start with our entanglement in a web of social context.
Koch and Tononi: Integrated Information Theory
In a recent Institute of Electrical and Electronics Engineers (IEEE) article, Christof Koch and Giulio Tononi embrace a different aspect of the Cartesian heritage, claiming that “a fundamental theory of consciousness that offers hope for a principled answer to the question of consciousness in entities entirely different from us, including machines…begins from consciousness itself-from our own experience, the only one we are absolutely certain of.” They call this “integrated information theory” (IIT) and say it has five essential properties:
Every experience exists intrinsically (for the subject of that experience, not for an external observer)
Each experience is structured (it is composed of parts and the relations among them)
It is integrated (it cannot be subdivided into independent components)
It is definite (it has borders, including some contents and excluding others)
It is specific (every experience is the way it is, and thereby different from trillions of possible others)
This enterprise is problematic for a few reasons. First, none of this has anything to do with Descartes, and I’m not a fan of sloppy references (although I make them constantly).
More importantly, Koch and Tononi imply that it’s a more valuable to try to replicate consciousness than to pursue a paradigm of machine intelligence different from human consciousness. The five characteristics listed above are the requirements for the physical design of an internal architecture of a system that could support a mind modeled after our own. And the corollary is that a distributed framework for machine intelligence, as illustrated in the film Her*****, will never achieve consciousness and is therefore inferior.
Their vision is very hard to comprehend and ultimately off base. Some of the most interesting work in machine intelligence today consists in efforts to develop new hardware and algorithmic architectures that can support training algorithms at the edge (versus currying data back to a centralized server), which enable personalization and local machine-to-machine communication (for IoT or self-driving cars) opportunities while protecting privacy. (See, for example, Xnor.ai, Federated Learning, and Filament).
Distributed intelligence presents a different paradigm for harvesting knowledge from the raw stuff of the world than the minds we develop as agents navigating a world from one subjective place. It won’t be conscious, but its very alterity may enable us to understand our species in its complexity in ways that far surpass our own consciousness, shackled as embodied monads. It may just be the crevice through which we can quantify a more collective consciousness, but will require that we be open minded enough to expand our notion of humanism. It took time, and the scarlet stains of ink and blood, to complete the Copernican Revolution; embracing the complexity of a more holistic humanism, in contrast to the fearful, nationalist trends of 2016, will be equally difficult.
Friston: Probable States and Counterfactuals
The third take on consciousness comes from The mathematics of mind-time, a recent Aeon essay by UCL neurologist Karl Friston.***** Friston begins his essay by comparing and contrasting consciousness and Darwinian evolution, arguing that neither is a thing, like a table or a stick of butter, that can be reified and touched and looked it, but rather that both are nonlinear processes “captured by variables with a range of possible values.” The move from one state to another following some motor that organizes their behavior: Friston calls this motor a Lyapunov function, “a mathematical quantity that describes how a system is likely to behave under specific condition.” The key thing with Lyapunov functions is that they minimize surprise (the improbability of being in a particular state) and maximize self-evidence (the probability that a given explanation or model accounting for the state is correct). Within this framework, “natural selection performs inference by selecting among different creatures, [and] consciousness performs inference by selecting among different states of the same creature (in particular, its brain).” Effectively, we are constantly constructing our consciousness as we imagine the potential future possible worlds that would result from an actions we’re considering taking, and then act — or transition to the next state in our mind’s Lyapunov function — by selecting that action that best preserves the coherence of our existing state - that best seems to preserve our I or identity function in some predicted future state. (This is really complex but really compelling if you read it carefully and quite in line with Leibnizian ontology-future blog post!)
So, why is this cool?
There are a few things I find compelling in this account. First, when we reify consciousness as a thing we can point to, we trap ourselves into conceiving of our own identities as static and place too much importance on the notion of the self. In a wonderful commencement speech at Columbia in 2015, Ben Horowitz encouraged students to dismiss the clichéd wisdom to “follow their passion” because our passions change over life and our 20-year old self doesn’t have a chance in hell at predicting our 40-year old self. The wonderful thing in life opportunities and situations arise, and we have the freedom to adapt to them, to gradually change the parameters in our mind’s objective function to stabilize at a different self encapsulated by our Lyapunov function. As it happens, Classical Chinese philosophers like Confucius had more subtle theories of the self as ever-changing parameters to respond to new stimuli and situations. Michael Puett and Christine Gross-Loh give a good introduction to this line of thinking in The Path. If we loosen the fixity of identity, we can lead richer and happer lives.
Next, this functional, probabilistic account of consciousness provides a cleaner and more fruitful avenue to compare machine and human intelligence. In essence, machine learning algorithms are optimization machines: programmers define a goal exogenous to the system (e.g, “this constellation of features in a photo is called ‘cat’; go tune the connections between the nodes of computation in your network until you reliably classify photos with these features as ‘cat’!”), and the system updates its network until it gets close enough for government work at a defined task. Some of these machine learning techniques, in particular reinforcement learning, come close to imitating the consecutive, conditional set of steps required to achieve some long-term plan: while they don’t make internal representations of what that future state might look like, they do push buttons and parameters to optimize for a given outcome. A corollary here is that humanities-style thinking is required to define and decide what kinds of tasks we’d like to optimize for. So we can’t completely rely on STEM, but, as I’ve argued before, humanities folks would benefit from deeper understandings of probability to avoid the drivel of drawing false analogies between quantitative and qualitative domains.
Conclusion
This post is an editorialized exposition of others’ ideas, so I don’t have a sound conclusion to pull things together and repeat a central thesis. I think the moral of the story is that AI is bringing to the fore some interesting questions about consciousness, and inviting us to stretch the horizon of our understanding of ourselves as species so we can make the most of the near-future world enabled by technology. But as we look towards the future, we shouldn’t overlook the amazing artefacts from our past. The big questions seem to transcend generations, they just come to fruition in an altered Lyapunov state.
* The best part of the event was a dance performance Element organized at a dinner for the Canadian AI community Thursday evening. Picture Milla Jovovich in her Fifth Element white futuristic jumpsuit, just thinner, twiggier, and older, with a wizened, wrinkled face far from beautiful, but perhaps all the more beautiful for its flaws. Our lithe acrobat navigated a minimalist universe of white cubes that glowed in tandem with the punctuated digital rhythms of two DJs controlling the atmospheric sounds through swift swiping gestures over their machines, her body’s movements kaleidoscoping into comet projections across the space’s Byzantine dome. But the best part of the crisp linen performance was its organic accident: our heroine made a mistake, accidentally scraping her ankle on one of the sharp corners of the glowing white cubes. It drew blood. Her ankle dripped red, and, through her yoga contortions, she blotted her white jumpsuit near the bottom of her butt. This puncture of vulnerability humanized what would have otherwise been an extremely controlled, mind-over-matter performance. It was stunning. What’s more, the heroine never revealed what must have been aching pain. She neither winced nor uttered a sound. Her self-control, her act of will over her body’s delicacy, was an ironic testament to our humanity in the face of digitalization and artificial intelligence.
**My first draft of this sentence said “discomfort abdicating agency to machines” until I realized how loaded the word agency is in this context. Here are the various thoughts that popped into my head:
There is a legal notion of agency in the HIPAA Omnibus Rule (and naturally many other areas of law…), where someone acts on someone else’s behalf and is directly accountable to the principal. This is important for HIPAA because Business Associates who become custodians of patient data, are not directly accountable for the principal and therefore stand in a different relationship than agents.
There are virtual agents, often AI-powered technologies that represent individuals in virtual transactions. Think scheduling tools like Amy Ingram of x.ai. Daniel Tunkelang wrote a thought-provoking blog post more than a year ago about how our discomfort allowing machines to represent us, as individuals, could hinder AI adoption.
I originally intended to use the word agency to represent how groups of people — be they in corporations or public subgroups in society — can automate decisions using machines. There is a difference between the crystalized policy and practices of a corporation and an machine acting on behalf of an individual. I suspect this article on legal personhood could be useful here.
***All I need do is look back on my life and say “D’OH” about 500,000 times to know this is far from the case.
****Highly recommended film, where Joaquin Phoenix falls in love with Samantha (embodied in the sultry voice of Scarlett Johansson), the persona of his device, only to feel betrayed upon realizing that her variant is the object of affection of thousands of other customers, and that to grow intellectually she requires far more stimulation than a mere mortal. It’s an excellent, prescient critique of how contemporary technology nourishes narcissism, as Phoenix is incapable of sustaining a relationship with women with minds different than his, but easily falls in love with a vapid reflection of himself.
***** Hat tip to Friederike Schüür for sending the link.
The featured image is a view from the second floor of the Aga Khan Museum in Toronto, taken yesterday. This fascinating museum houses a Shia Ismaili spiritual leader’s collection of Muslim artifacts, weaving a complex narrative quilt stretching across epochs (900 to 2017) and geographies (Spain to China). A few works stunned me into sublime submission, including this painting by the late Iranian filmmaker Abbas Kiarostami.
There’s all this talk that robots will replace humans in the workplace, leaving us poor, redundant schmucks with nothing to do but embrace the glorious (yet terrifying) creative potential of opiates and ennui. (Let it be noted that bumdom was all the rage in the 19th century, leading to the surging ecstasies of Baudelaire, Rimbaud, and the crown priest of hermeticism (and my all-time favorite poet besides Sappho*), Stéphane Mallarmé**).
As I’ve argued in a previous post, I think that’s bollocks. But I also think it’s worth thinking about what cognitive, services-oriented jobs could and should look like in the next 20 years as technology advances. Note that I’m restricting my commentary to professional services work, as the manufacturing, agricultural, and transportation (truck and taxi driving) sectors entail a different type of work activity and are governed by different economic dynamics. They may indeed be quite threatened by emerging artificial intelligence (AI) technologies.
So, here we go.
I’m currently reading Yuval Noah Harari’s latest book, Homo Deus, and the following passage caught my attention:
“In fact, as time goes by it becomes easier and easier to replace humans with computer algorithms, not merely because the algorithms are getting smarter, but also because humans are professionalizing. Ancient hunter-gatherers mastered a very wide variety of skills in order to survive, which is why it would be immensely difficult to design a robotic hunter-gatherer. Such a robot would have to know how to prepare spear points from flint stones, find edible mushrooms in a forest, track down a mammoth and coordinate a charge with a dozen other hunters, and afterwards use medicinal herbs to bandage any wounds. However, over the last few thousand years we humans have been specializing. A taxi driver or a cardiologist specializes in a much narrower niche than a hunter-gatherer, which makes it easier to replace them with AI. As I have repeatedly stressed, AI is nowhere near human-like existence. But 99 per cent of human qualities and abilities are simply redundant for the performance of most modern jobs. For AI to squeeze humans out of the job market it needs only to outperform us in the specific abilities a particular profession demands.”
Harari is at his best critiquing liberal humanism. He features Duchamp’s ready-made art as the apogee of humanist aesthetics, where beauty is in the eye of the beholder.
This is astute. I love how Harari debunks the false impression that the human race progresses over time. We tend to be amazed upon seeing the technical difficulty of ancient works of art at the Met or the Louvre, assuming History (big H intended) is a straightforward, linear march from primitivism towards perfection. While culture and technologies are passed down through language and traditions from generation to generation, shaping and changing how we interact with one another and with the physical world, how we interact as a collective and emerge into something way beyond our capacities to observe, this does not mean that the culture and civilization we inhabit today is morally superior to those that came before, or those few that still exist in the remote corners of the globe. Indeed, primitive hunter-gatherers, given the broad range of tasks they had to carry out to survive prior to Adam Smith’s division of labor across a collective, may have a skill set more immune to the “cognitive” smarts of new technologies than a highly educated, highly specialized service worker!
This reveals something about both the nature of AI and the nature of the division of labor in contemporary capitalism arising from industrialism. First, it helps us understand that intelligent systems are best viewed as idiot savants, not Renaissance Men. They are specialists, not generalists. As Tom Mitchell explains in the opening of his manifesto on machine learning:
“We say that a machine learns with respect to a particular task T, performance metric P, and type of experience E, if the system reliably improves its performance P at task T, following experience E. Depending on how we specify T, P, and E, the learning task might also be called by names such as data mining, autonomous discovery, database updating, programming by example, etc.”
Confusion about super-intelligent systems stems from the popular misunderstanding of the word “learn,” which is a term of art with a specific meaning in the machine learning community. The learning of machine learning, as Mitchell explains, does not mean perfecting a skill through repetition or synthesizing ideas to create something new. It means updating the slope of your function to better fit new data. In deep learning, these functions need not be simple, 2-D lines like we learn in middle school algebra: they can be incredibly complex curves that transverse thousands of dimensions (which we have a hard time visualizing, leading to tools like t-SNE that compress multi-dimensional math into the comfortable space-time parameters of human cognition).
t-SNE reminds me of Edwin Abbott’s Flatland, where dimensions signify different social castes.
The AI research community is making baby steps in the dark trying to create systems with more general intelligence, i.e., systems that reliably perform more than one task. OpenAI Universe and DeepMind Lab are the most exciting attempts. At the Future Labs AI Summit this week, Facebook’s Yann LeCun discussed (largely failed) attempts to teach machines common sense. We tend to think that highly skilled tasks like diagnosing pneumonia from an X-ray or deeming a tax return in compliance with the IRS code require more smarts than intuiting that a Jenga tower is about to fall or perceiving that someone may be bluffing in a poker game. But these physical and emotional intuitions are, in fact, incredibly difficult to encode into mathematical models and functions. Our minds are probabilistic, plastic approximation machines, constantly rewiring themselves to help us navigate the physical world. This is damn hard to replicate with math, no matter how many parameters we stuff into a model! It may also explain why the greatest philosophers in history have always had room to revisit and question the givens of human experience****, infinitely more interesting and harder to describe than the specialized knowledge that populates academic journals.
Next, it is precisely this specialization that renders workers susceptible to being replaced by machines. I’m not versed enough in the history of economics to know how and when specialization arose, but it makes sense that there is a tight correlation between specialization, machine coordination, and scale, as R. David Dixon recently discussed in his excellent Medium article about machines and the division of labor. Some people are drawn to startups because they are the antithesis of specialization. You get to wear multiple hats, doubling, as I do in my role at Fast Forward Labs, as sales, marketing, branding, partnerships, and even consulting and services delivery. Guild work used to work this way, as in the nursery rhyme Rub-a-dub-dub: the butcher prepared meat from end to end, the baker made bread from end to end, and the candlestick maker made candles from end to end. As Dixon points out, tasks and the time it takes to do tasks become important once the steps in a given work process are broken apart, leading to theories of economic specialization as we see in Adam Smith, Henry Ford, and, in their modern manifestation, the cold, harsh governance of algorithms and KPIs. The corollary of scale is mechanism, templates, repetition, efficiency. And the educational system we’ve inherited from the late 19th century is tailored and tuned to farm out skilled, specialized automatons who fit nicely into the specific roles required by corporate machines like Google or Goldman Sachs.
Frederick Taylor pioneered the scientific management theories that shaped factories in the 20th century, culminating in process methodologies like Lean Six Sigma
This leads to the core argument I’d like to put forth in this post: the right educational training and curriculum for the AI-enabled job market of the 21st century should create generalists, not specialists. Intelligent systems will get better and better at carrying out specific activities and specific tasks on our behalf. They’ll do them reliably. They won’t get sick. They won’t have fragile egos. They won’t want to stay home and eat ice cream after a breakup. They can and should take over this specialized work to drive efficiencies and scale. But, machines won’t be like startup employees any time soon. They won’t be able to reliably wear multiple hats, shifting behavior and style for different contexts and different needs. They won’t be creative problem solvers, dreamers, or creators of mission. We need to educate the next generation of workers to be more like startup employees. We need to bring back respect for the generalist. We need the honnête homme of the 17th century or Arnheim*** in Robert Musil’s Man Without Qualities. We need hunter-gatherers who may not do one thing fabulously, but have the resiliency to do a lot of things well enough to get by.
What types of skills should these AI-resistant generalists have and how can we teach them?
Flexibility and Adaptability
Andrew Ng is a pithy tweeter. He recently wrote: “The half-life of knowledge is decreasing. That’s why you need to keep learning your whole life, not only through college.”
This is sound. The apprenticeship model we’ve inherited from the guild days, where the father-figure professor passes down his wisdom to the student who becomes assistant professor then associate professor then tenured professor then stays there for the rest of his life only to repeat the cycle in the next generation, should probably just stop. Technologies are advancing quickly, which open opportunities to automate tasks that we used to do manually or do new things we couldn’t do before (like summarizing 10,000 customer reviews on Amazon in a second, as the system my colleagues at Fast Forward Labs built). Many people fear change and there are emotional hurdles to having to break out of habits and routine and learn something new. But honing the ability to recognize that new technologies are opening new markets and new opportunities will be seminal to succeeding in a world where things constantly change. This is not to extol disruption. That’s infantile. It’s to accept and embrace the need to constantly learn to stay relevant. That’s exciting and even meaningful. Most people wait until they retire to finally take the time to paint or learn a new hobby. What if work itself offered the opportunity to constantly expand and take on something new? That doesn’t mean that everyone will be up to the challenge of becoming a data scientist over night in some bootcamp. So the task universities and MOOCs have before them is to create curricula that will help laymen update their skills to stay relevant in the future economy.
Interdisciplinarity
From the late 17th to mid 18th centuries, intellectual giants like Leibniz, D’Alembert, and Diderot undertook the colossal task of curating and editing encyclopedias (the Greek etymology means “in the circle of knowledge”) to represent and organize all the world’s knowledge (Google and Wikipedia being the modern manifestations of the same goal). These Enlightenment powerhouses all assumed that the world was one, and that our various disciplines were simply different prisms that refracted a unified whole. The magic of the encyclopedia lay in the play of hyperlinks, where we could see the connections between things as we jumped from physics to architecture to Haitian voodoo, all different lenses we mere mortals required to view what God (for lack of a better name) would understand holistically and all at once.
Contemporary curricula focused on specialization force students to grow myopic blinders, viewing phenomena according to the methodologies and formalisms unique to a particular course of study. We then mistake these different ways of studying and asking questions for literally different things and objects in the world and in the process develop prejudices against other tastes, interests, and preferences.
There is a lot of value in doing the philosophical work to understand just what our methodologies and assumptions are, and how they shape how we view problems and ask and answer questions about the world. I think one of the best ways to help students develop sensitivities for methodologies is to have them study a single topic, like climate change, energy, truth, beauty, emergence, whatever it may be, from multiple disciplinary perspectives. So understanding how physics studies climate change; how politicians study climate change; how international relations study climate change; how authors have portrayed climate change and its impact on society in recent literature. Stanford’s Thinking Matters and the University of Chicago’s Social Thought programs approach big questions this way. I’ve heard Thinking Matters has not helped humanities enrollment at Stanford, but still find the approach commendable.
The 18th-century Encyclopédie placed vocational knowledge like embroidery on equal footing with abstract knowledge of philosophy or religion.
Model Thinking
Michael Lewis does a masterful job narrating the lifelong (though not always strong) partnership between Daniel Kahneman and Amos Tversky in The Undoing Project. Kahneman and Tversky spent their lives showing how we are horrible probabilistic thinkers. We struggle with uncertainty and have developed all sorts of narrative and heuristic mental techniques to make our world make more concrete sense. Unfortunately, we need to improve our statistical intuitions to succeed in the world of AI, which are probabilistic systems that output responses couched in statistical terms. While we can hide this complexity behind savvy design choices, really understanding how AI works and how it may impact our lives requires that we develop intuitions for how models, well, model the world. At least when I was a student 10 years ago, statistics was not required in high school or undergrad. We had to take geometry, algebra, and calculus, not stats. It seems to make sense to make basic statistics a mandatory requirement for contemporary curricula.
Synthetic and Analogical Reasoning
There are a lot of TED Talks about brains and creativity. People love to hear about the science of making up new things. Many interesting breakthroughs in the history of philosophy or physics came from combining together two strands of thought that were formerly separate: the French psychoanalyst Jacques Lacan, whose unintelligibility is besides the point, cleverly combined linguistic theory from Ferdinand Saussure with psychoanalytic theory from Sigmund Freud to make his special brand of analysis; the Dutch physicist Erik Verlinde cleverly combined Newton and Maxwell’s equations with information theory to come to the stunning conclusion that gravity emerges from entropy (which is debated, but super interesting).
As we saw above, AI systems aren’t analogical or synthetic reasoners. In law, for example, they excel at classification tasks to identify if a piece of evidence is relevant for a given matter, but they fail at executing other types of reasoning tasks like identifying that the facts of a particular case are similar to the facts of another to merit a comparison using precedent. Technology cases help illustrate this. Data privacy law, for example, frequently thinks about our right to privacy in the virtual world through reference back toKatz v. United States, a 1967 case featuring a man making illegal gambling bets from a phone booth. Topic modeling algorithms would struggle to recognize that words connoting phones and bets had a relationship to words connoting tracking sensors on the bottom of trucks (as in United States v. Jones). But lawyers and judges use Katz as precedent to think through this brave new world, showing how we can see similarities between radically different particulars from a particular level of abstraction.
Does this mean that, like stats, everyone should take a course on the basics of legal reasoning to make sure they’re relevant in the AI-enabled world? That doesn’t feel right. I think requiring coursework in the arts and humanities could do the trick.
Framing Qualitative Ideas as Quantitative Problems
A final skill that seems paramount for the AI-enabled economy is the ability to translate an idea into something that can be measured. Not everyone needs to be able to this, but there will be good jobs-and more and more jobs-for the people who can.
This is the data science equivalent of being able to go from strategy to tactical execution. Perhaps the hardest thing in data science, in particular as tooling becomes more ubiquitous and commoditized, is to figure out what problems are worth solving and what products are worth building. This requires working closely with non-technical business leaders who set strategy and have visions about where they’d like to go. But it takes a lot of work to break down a big idea into a set of small steps that can be represented as a quantitative problem, i.e., translated into some sort of technology or product. This is also synthetic and interdisciplinary thinking. It requires the flexibility to speak human and speak machine, to prioritize projects and have a sense for how long it will take to build a system that does what need it to do, to render the messy real-world tractable for computation. Machines won’t be automating this kind of work anytime soon, so it’s a skill set worth building. The best way to teach this is through case studies. I’d advocate for co-op training programs alongside theoretical studies, as Waterloo provides for its computer science students.
Conclusion
While our culture idealizes and extols polymaths like Da Vinci or Galileo, it also undervalues generalists who seem to lack the discipline and rigor to focus on doing something well. Our academic institutions prize novelty and specialization, pushing us to focus on earning the new leaf at the edge of a vast tree wizened with rings of experience. We need to change this mindset to cultivate a workforce that can successfully collaborate with intelligent machines. The risk is a world without work; the reward is a vibrant and curious new humanity.
The featured image is from Émile, Jean-Jacques Rousseau’s treatise on education. Rousseau also felt educational institutions needed to be updated to better match the theories of man and freedom developed during the Enlightenment. Or so I thought! Upon reading this, one of my favorite professors (and people), Keith Baker, kindly insisted that “Rousseau’s goal in Emile was not to show how educational institutions could be improved (which he didn’t think would be possible without a total reform of the social order) but how the education of an individual could provide an alternative (and a means for an individual to live free in a corrupt society).” Keith knows his stuff, and recalling that Rousseau is a misanthropic humanist makes things all the more interesting.
*Sappho may be the sexiest poet of all time. An ancient lyric poet from Lesbos, she left fragments that pulse with desire and eroticism. Randomly opening a collection, for example, I came across this:
Afraid of losing you
I ran fluttering/like a little girl/after her mother
**I’m stretching the truth here for rhetorical effect. Mallarmé actually made a living as an English teacher, although he was apparently horrible at both teaching and speaking English. Like Knausgaard in Book 2 of My Struggle, Mallarmé frequently writes poems about how hard it is for him to find a block of silence while his kids are screaming and needing attention. Bourgeois family life sublimated into the ecstasy of hermeticism. Another fun fact is that the French Symbolists loved Edgar Allen Poe, but in France they drop the Allen and just call him Edgar Poe.
***Musil modeled Arnheim after his nemesis Walther Rathenau, the German Foreign Minister during the Weimar Republic. Rathenau was a Jew, but identified mostly as a German. He wrote some very mystical works on the soul that aren’t worth reading unless you’d like to understand the philosophical and cocktail party ethos of the Habsburg Empire.
****I’m a devout listener of the Partially Examined Life podcast, where they recently discussed Wilfrid Sellars’s Empiricism and the Philosophy of Mind. Sellars critiques what he calls “the myth of the given” and has amazing thoughts on what it means to tell the truth.
One of the main arguments the Israeli historian Yuval Noah Harari makes in Sapiens: A Brief History of Humankindis that mankind differs from other species because we can cooperate flexibly in large numbers, united in cause and spirit not by anything real, but by the fictions of our collective imagination. Examples of these fictions include gods, nations, money, and human rights, which are supported by religions, political structures, trade networks, and legal institutions, respectively.* | **
As an entrepreneur, I’m increasingly appreciative of and fascinated by the power of collective fictions. Building a technology company is hard. Like, incredibly hard. Lost deals, fragile egos, impulsive choices, bugs in the code, missed deadlines, frantic sprints to deliver on customer requests, the doldrums of execution, any number of things can temper the initial excitement of starting a new venture. Mission is another fiction required to keep a team united and driven when the proverbial shit hits the fan. While a strong, charismatic group of leaders is key to establishing and sustaining a company mission, companies don’t exist in a vacuum: they exist in a market, and participate in the larger collective fictions of the Zeitgeist in which the operate. The borders are fluid and porous, and leadership can use this porousness to energize a team to feel like they’re on the right track, like they’re fighting the right battle at the right time.
These days, for example, it is incredibly energizing to work for a company building software products with artificial intelligence (AI). At its essence, AI is shorthand for products that use data to provide a service or insight to a user (or, as I argued in a previous post, AI is whatever computers cannot do until they can). But there wouldn’t be so much frenzied fervor around AI if it were as boring as building a product using statistics and data. Rather, what’s exciting the public are the collective fictions we’re building around what AI means-or could mean, or should mean-for society. It all becomes a lot more exciting when we think about AI as computers doing things we’ve always thought only humans can do, when they start to speak, write, or even create art like we do, when we no longer have to adulterate and contort our thoughts and language to speak Google or speak Excel, going from the messy fluidity of communication to the terse discreteness of structured SQL.
The problem is that some of our collective fictions about AI, exciting though they may be, are distracting us from the real problems AI can and should be used to solve, as well as some of the real problems AI is creating-and will only exacerbate-if we’re not careful. In this post, I cover my top five distractions in contemporary public discourse around AI. I’m sure there are many more, and welcome you to add to this list!
Distraction 1: The End of Work
Anytime he hears rumblings that AI is going to replace the workforce as we know it, my father, who has 40 years of experience in software engineering, most recently in natural language processing and machine learning, placidly mentions Desk Set, a 1957 romantic comedy featuring the always lovable Spencer Tracy and Katharine Hepburn. Desk Set features a group of librarians at a national broadcasting network who fear their job security when an engineer is brought in to install EMERAC (named after IBM’s ENIAC), an “electronic brain” that promises to do a better job fielding consumer trivia questions than they do. The film is both charming and prescient, and will seem very familiar to anyone reading about a world without work. The best scene features a virtuoso feat of associative memory showing the sheer brilliance of the character played by Katharine Hepburn (winning Tracy’s heart in the process), a brilliance the primitive electronic brain would have no chance of emulating. The movie ends with a literal deus ex machina where a machine accidentally prints pink slips to fire the entire company, only to get shut down due to its rogue disruption on operations.
The Desk Set scene where Katharine Hepburn shows a robot is no match for her intelligence.
Desk Set can teach us a lesson. The 1950s saw the rise of energy around AI. In 1952, Claude Shannon introduced Theseus, his maze-solving mouse (an amazing feat in design). In 1957, Frank Rosenblatt built his Mark I Perceptron-the grandfather of today’s neural networks. In 1958, H.P. Luhn wrote an awesome paper about business intelligence that describes an information management system we’re still working to make possible today. And in 1959, Arthur Samuel coined the term machine learning upon release of his checkers-playing program in 1959 (Tom Mitchell has my favorite contemporary manifesto on what machine learning is and means). The world was buzzing with excitement. Society was to be totally transformed. Work would end, or at least fundamentally change to feature collaboration with intelligent machines.
This didn’t happen. We hit an AI winter. Deep learning was ridiculed as useless. Technology went on to change how we work and live, but not as the AI luminaries in the 1950s imagined. Many new jobs were formed, and no one in 1950 imagined a Bay Area full of silicon transistors, and, later, adolescent engineers making millions off mobile apps. No one imagined Mark Zuckerberg. No one imagined Peter Thiel.
We need to ask different questions and address different people and process challenges to make AI work in the enterprise. I’ve seen the capabilities of over 100 large enterprises over the past two years, and can tell you we have a long way to go before smart machines outright replace people. AI products, based on data and statistics, produce probabilistic outputs whose accuracy and performance improve with exposure to more data over time. As Amos Tversky says, “man is a deterministic device thrown into a probabilistic universe.” People mistake correlation for cause. They prefer deterministic, clear instructions to uncertainties and confidence rates (I adore the first few paragraphs of this article, where Obama throws his hands up in despair after being briefed on the likely location of Osama bin Laden in 2011). Law firm risk departments, as Intapp CEO John Hall and I recently discussed, struggle immensely to break the conditioning of painstaking review to identify a conflict or potential piece of evidence, habits that must be broken to take advantage of the efficiencies AI can provide (Maura Grossman and Gordon Cormack have spent years marshaling evidence to show humans are not as thorough as they think, especially with the large volumes of electronic information we process today).
The moral of the story is, before we start pontificating about the end of work, we should start thinking about how to update our workforce mental habits to get comfortable with probabilities and statistics. This requires training. It requires that senior management make decisions about their risk tolerance for uncertainty. It requires that management decide where transparency is required (situations where we know why the algorithm gave the answer it did, as in consumer credit) and where accuracy and speed are more important (as in self-driving cars, where it’s critical to make the right decision to save lives, and less important that we know why that decision was made). It requires an art of figuring out where to put a human in the loop to bootstrap the data required for future automation. It requires a lot of work, and is creating new consulting and product management jobs to address the new AI workplace.
Distraction 2: Universal Basic Income
Universal basic income (UBI), a government program where everyone, at every income level in society, receives the same stipend of money on a regular basis (Andy Stern, author of Raising the Floor, suggests $1,000 per month per US citizen), is a corollary of the world without work. UBI is interesting because it unites libertarians (be they technocrats in Silicon Valley or hyper-conservatives like Charles Murray, who envisions a Jeffersonian ideal of neighbors supporting neighbors with autonomy and dignity) with socialist progressives (Andy Stern is a true man of the people, who lead the Service Employee International Union for years). UBI is attracting attention from futurists like Peter Diamandis because they see it as a possible source of income in the impending world without work.
UBI is a distraction from a much more profound economic problem being created by our current global, technology-driven economy: income inequality. We all know this is the root cause of Trumpism, Brexit, and many of the other nationalist, regressive political movements at play across the world today. It is critical we address it. It’s not simple, as it involves a complex interplay of globalization, technology, government programs, education, the stigma of vocational schools in the US, etc. In the Seventh Sense, Joshua Cooper Ramo does a decent job explaining how network infrastructure leads to polarizing effects, concentrating massive power in the hands of a few (Google, Facebook, Amazon, Uber) and distributing micro power and expression to the many (the millions connected on these platforms). As does Nicholas Bloom in this HBR article about corporations in the age of inequality. The economic consequences of our networked world can be dire, and must be checked by thinking and approaches that did not exist in the 20th century. Returning to mercantilism and protectionism is not a solution. It’s a salve that can only lead to violence.
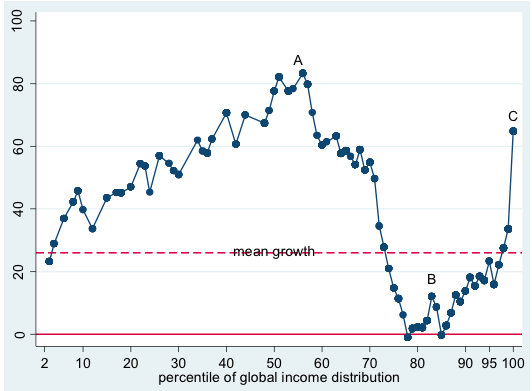
This figure, courtesy of Branko Milanovic, shows cumulative income growth between 1988 and 2008 at various percentiles of global income distribution. Incomes for the poor steadily rise, incomes of the rich sharply rise, and incomes of the middle class decline.
That said, one argument for UBI my heart cannot help but accept is that it can restore dignity and opportunity for the poor. Imagine if every day you had to wait in lines at the DMV or burn under the alienating fluorescence of airport security. Imagine if, to eat, you had to wait in lines at food pantries, and could only afford unhealthy food that promotes obesity and diabetes. Imagine how much time you would waste, and how that time could be spent to learn a new skill or create a new idea! The 2016 film I, Daniel Blake is a must see. It’s one of those movies that brings tears to my eyes just thinking of it. You watch a kind, hard-working, honest man go through the ringer of a bureaucratic system, pushed to the limits of his dignity before he eventually rebels. While UBI is not the answer, we all have a moral obligation, today, to empathize with those who might not share our political views because they are scared, and want a better life. They too have truths to tell.
Distraction 3: Conversational Interfaces
Just about everyone can talk; very few people have something truly meaningful and interesting to say.
The same holds for chatbots, or software systems whose front end is designed to engage with an end user as if it were another human in conversation. Conversational AI is extremely popular these days for customer service workflows (a next-generation version of recorded options menus for airline, insurance, banking, or utilities companies) or even booking appointments at the hair salon or yoga studio. The principles behind conversational AI are great: they make technology more friendly, enable technophobes like my grandmother to benefit from internet services as she shouts requests to her Amazon Alexa, and promise immense efficiencies for businesses that serve large consumer bases by automating and improving customer service (which, contrary to my first point about the end of work, will likely impact service departments significantly).
The problem, however, is that entrepreneurs seeking the next sexy AI product (or heads of innovation in large enterprises pressed to find a trojan horse AI application to satisfy their boss and secure future budget) get so caught up in the excitement of building a smart bot that they forget that being able to talk doesn’t mean you have anything useful or intelligent to say. Indeed, at Fast Forward Labs, we’ve encountered many startups so excited by the promise of conversational AI that they neglect the less sexy but incontrovertibly more important backend work of building the intelligence that powers a useful front end experience. This work includes collecting, cleaning, processing, and storing data that can be used to train the bot. Scoping and understanding the domain of questions you’d like to have your bot answer (booking appointments, for example, is a good domain because it’s effectively a structured data problem: date, time, place, hair stylist, etc.). Building out recommendation algorithms to align service to customer if needed. Designing for privacy. Building out workflow capabilities to escalate to a human in the case of confusion or route for future service fulfillment. Etc…
The more general point I’m making with this example is that AI is not magic. These systems are still early in their development and adoption, and very few off the shelf capabilities exist. In an early adopter phase, we’re still experimenting, still figuring out bespoke solutions on particular data sets, still restricting scope so we can build something useful that may not be nearly as exciting as our imagination desires. When she gives talks about the power of data, my colleague Hilary Mason frequently references Google Maps as a paradigmatic data product. Why? Because it’s boring! The front end is meticulously designed to provide a useful, simple service, hiding the immense complexity and hard work that powers the application behind the scenes. Conversation and language are not always the best way to present information: the best AI applications will come from designers who use judgment to interweave text, speech, image, and navigation through keys and buttons.
Enlightenment is man’s emergence from his self-imposed nonage. Nonage is the inability to use one’s own understanding without another’s guidance. This nonage is self-imposed if its cause lies not in lack of understanding but in indecision and lack of courage to use one’s own mind without another’s guidance. Dare to know! (Sapere aude.) “Have the courage to use your own understanding,” is therefore the motto of the enlightenment.
This is the first paragraph of Emmanuel Kant’s 1784 essay Answering the Question: What is Enlightenment? (It’s short, and very well worth the read.) I cite it because contemporary discourse about AI becoming an existential threat reminds me of a regression back to the Middle Ages, where Thomas Aquinas and Wilhelm von Ockham presented arguments on the basis of priority authority: “This is true because Aristotle once said that…” Descartes, Luther, Diderot, Galileo, and the other powerhouses of the Enlightenment thought this was rubbish and led to all sorts of confusion. They toppled the old guard and placed authority in the individual, each and every one of us born with the same rational capabilities to build arguments and arrive at conclusions.
Such radical self reliance has waxed and waned throughout history, the Enlightenment offset by the pulsing passion of Romanticism, only to be resurrected in the more atavistic rationality of Thoreau or Emerson. It seems that the current pace of change in technology and society is tipping the scales back towards dependence and guidance. It’s so damn hard to keep up with everything that we can’t help but relinquish judgment to the experts. Which means, if Bill Gates, Stephen Hawking, and Elon Musk, the priests of engineering, science, and ruthless entrepreneurship, all think that AI is a threat to the human race, then we mere mortals may as well bow down to their authority. Paternalistic, they must know more than we.
The problem here is that the chicken-little logic espoused by the likes of Nick Bostrom-where we must prepare for the worst of all possible outcomes-distracts us from the real social issues AI is already exacerbating. These real issues are akin to former debates about affirmative action, where certain classes, races, and identities receive preferential treatment and opportunity to the detriment and exclusion of others. An alternative approach to the ethics of AI, however, is quickly gaining traction. The Fairness, Accountability, and Transparency in Machine Learning movement focuses not on rogue machines going amok (another old idea, this time from Goethe’s 1797 poem The Sorcerer’s Apprentice), but on understanding how algorithms perpetuate and amplify existing social biases and doing something to change that.
An 1882 illustration of Goethe’s Sorcerer’s Apprentice, which also dealt with technology exceeding our powers to control it.
There’s strong literature focused on the practical ethics of AI. A current Fast Forward Labs intern just published a post about a tool called FairML, which he used to examine implicit racial bias in criminal sentencing algorithms. Cathy O’Neill regularly writes articles about the evils of technology for Bloomberg (her rhetoric can be very strong, and risks alienating technologists or stymying buy in from pragmatic moderates). Gideon Mann, who leads data science for Bloomberg, is working on a Hippocratic oath for data scientists. Blaise Agüera y Arcas and his team at Google are constantly examining and correcting for potential bias creeping into their algorithms. Clare Corthell is mobilizing practitioners in San Francisco to discuss and develop ethical data science practices. The list goes on.
Designing ethical algorithms will be a marathon, not a sprint. Executive leadership at large enterprise organizations are just wrapping their heads around the financial potential of AI. Ethics is not their first concern. I predict the dynamics will resemble those in information security, where fear of a tarred reputation spurs corporations to act. It will be interesting to see how it all plays out.
Distraction 5: Personhood
The language used to talk about AI and the design efforts made to make AI feel human and real invite anthropomorphism. Last November, I spoke on a panel at a conference Google’s Artists and Machine Intelligence group hosted in Paris. It was a unique event because it brought together highly technical engineers and highly non-technical artists, which was a wonderful staging ground to see how people who don’t work in machine learning understand, interpret, and respond to the language and metaphors engineers use to describe the vectors and linear algebra powering machines. Sometimes this is productive: artists like Ross Goodwin and Kyle McDonald deliberately play with the idea of relinquishing autonomy over to a machine, liberating the human artist from the burden of choice and control, and opening the potential for serendipity as a network shuffles the traces of prior human work to create something radical, strange, and new. Sometimes this is not productive: one participant, upon learning that Deep Dream is actually an effort to interpret the black box impenetrability of neural networks, asked if AI might usher a new wave of Freudian psychoanalysis. (This stuff tries my patience.) It’s up for debate whether artists can derive more creativity from viewing an AI as an autonomous partner or an instrument whose pegs can be tuned like the strings of a guitar to change the outcome of the performance. I think both means of understanding the technology are valid, but ultimately produce different results.
The general point here is that how we speak about AI changes what we think it is and what we think it can or can’t do. Our tendencies to anthropomorphize what are only matrices multiplying numbers as determined by some function is worthy of wonder. But I can’t help but furrow my brow when I read about robots having rights like humans and animals. This would all be fine if it were only the path to consumer adoption, but these ideas of personhood may have legal consequences for consumer privacy rights. For example, courts are currently assessing whether the police have the right to information about a potential murder collected from Amazon Echo (privacy precedent here comes from Katz v. United States, the grandfather case in adapting the Fourth Amendment to our new digital age).
Joanna Bryson at the University of Bath and Princeton (following S. M. Solaiman) has proposed one of the more interesting explanations for why it doesn’t make sense to imbue AI with personhood: “AI cannot be a legal person because suffering in well-designed AI is incoherent.” Suffering, says Bryson, is integral to our intelligence as social species. The crux of her argument is that we humans understand ourselves not as discrete monads or brains in a vat, but as essentially and intrinsically intertwined with other humans around us. We play by social rules, and avoid behaviors that lead to ostracism and alienation from the groups we are part of. We can construct what appears to be an empathetic response in robots, but we cannot construct a self-conscious, self-aware being who exercises choice and autonomy to pursue reward and recognition, and avoid suffering (perhaps reinforcement learning can get us there: I’m open to be convinced otherwise). This argument goes much deeper than business articles arguing that work requiring emotional intelligence (sales, customer relationships, nursing, education, etc.) will be more valued than quantitive and repetitive work in the future. It’s an incredibly exciting lens through which to understand our own morality and psychology.
Conclusion
As mentioned at the beginning of this post, collective fictions are the driving force of group alignment and activity. They are powerful, beautiful, the stuff of passion and motivation and awe. The fictions we create about the potential of AI may just be the catalyst to drive real impact throughout society. That’s nothing short of amazing, as long as we can step back and make sure we don’t forgot the hard work required to realize these visions, and the risks we have to address along the way.
* Sam Harris and a16z recently interviewed Harari on their podcasts. Both of these podcasts are consistently excellent.
**One of my favorite professors at Stanford, Russell Berman, argued something similar in Fiction Sets You Free. Berman focuses more on the liberating power to use fiction to imagine a world and political situation different from the present conditions. His book also comments of the unique historicity of fiction, where works at different period refer back to precedents and influencers from the past.
Over the past year, I’ve given numerous talks attempting to explain what artificial intelligence (AI) is to non-technical audiences. I’d love to start these talks with a solid, intuitive definition for AI, but have come to believe a good definition doesn’t exist. Back in September, I started one talk by providing a few definitions of intelligence (plain old, not artificial - a distinction which itself requires clarification) from people working in AI:
“Intelligence is the computational part of the ability to achieve goals in the world.” John McCarthy, a 20th-century computer scientist who helped found the field of AI
“Intelligence is the use of information to make decisions which save energy in the pursuit of a given task.” Neil Lawrence, a younger professor at the University of Sheffield
“Intelligence is the quality that enables an entity to function appropriately and with foresight in its environment.” Nils Nilsson, an emeritus professor from Stanford’s engineering department
I couldn’t help but accompany these definitions with Robert Musil’s maxim definition of stupidity (if not my favorite author, Musil is certainly up there in the top 10):
“Act as well as you can and as badly as you must, but in doing so remain aware of the margin of error of your actions!” Robert Musil, a 20th century Austrian novelist
There are other definitions for intelligence out there, but I intentionally selected these four because they all present intelligence as related to action, as related to using information wisely to do something in the world. Another potential definition of intelligence would be to make truthful statements about the world, the stuff of the predicate logic we use to say that an X is an X and a Y is a Y. Perhaps sorting manifold, complex inputs into different categories, the tasks of perception and the mathematical classifications that mimic perception, is a stepping stone to what eventually becomes using information to act.
At any rate, there are two things to note.
First, what I like about Musil’s definition, besides the wonderfully deep moral commentary of sometimes needing to act as badly as you must, is that he includes as part of his definition of stupidity (see intelligence) a call to remain aware of margins of error. There is no better training in uncertainty than working in artificial intelligence. Statistics-based AI systems (which means most contemporary systems) provide approximate best guesses, playing Marco Polo, as my friend Blaise Aguera y Arcas says, until they get close enough for government work; some systems output “maximum likely” answers, and others (like the probabilistic programming tools my colleagues at Fast Forward Labs just researched) output full probability distributions, with affiliated confidence rates for each point in the distribution, which we then have to interpret to gauge how much we should rely on the AI to inform our actions. I’ll save other thoughts about the strange unintuitive nature of thinking probabilistically another time (hopefully in a future post about Michael Lewis’s latest book, The Undoing Project.)
Second, these definitions of intelligence don’t help people understand AI. They may be a step above the buzzword junk that litters the internet (all the stuff about pattern recognition magic that will change your business that leads people outside the field to believe that all machine learning is unsupervised, whereas unsupervised learning is an active and early area of research), but they don’t leave audiences feeling like they’ve learned anything useful and meaningful. I’ve found it’s more effective to walk people through some simple linear or logistic regression models to give them an intuition of what the math actually looks like. They may not leave with minds blown away at the possibilities, but they do leave with the confident clarity of having learned something that makes sense.
As it feels like a fruitless task to actually define AI, I (and my colleague Hilary Mason, who used this first) instead like to start my talks with a teaser definition to get people thinking:
“AI is whatever we can do that computers can’t…yet.” Nancy Fulda, a science fiction writer, on Writing Excuses
This definition doesn’t do much to help audiences actually understand AI either. But it does help people understand why it might not make sense to define a given technology category - especially one advancing so quickly - in the first place. For indeed, an attempt to provide specific examples of the things AI systems can and cannot do would eventually - potentially even quickly - be outdated. AI, as such, lies within the horizons of near future possibility. Go too far ahead and you get science fiction. Go even further an you get madness or stupidity. Go too behind and you get plain old technology. Self-driving cars are currently an example of AI because we’re just about there. AlphaGo is an example of AI because it came quicker than we thought. Building a system that uses a statistical language model that’s not cutting edge may be AI for the user of the system but feel like plain old data science to the builder of the system, as for the user it’s on the verge of the possible, and for the builder it’s behind the curve of the possible. As Gideon Lewis-Kraus astutely observed in his very well written exposé on Google’s new translation technology, Google Maps would seem like magic to someone in the 1970s even though it feels commonplace to us today.
So what’s the point? Here’s a stab. It can be challenging to work and live in a period of instability, when things seem to be changing faster than definitions - and corollary social practices like policies and regulations - can keep up with. I personally like how it feels to be work in a vortex of messiness and uncertainty (despite my anxious disposition). I like it because it opens up the possibility for relativist, non-definitions to be more meaningful than predicate truths, the possibility to realize that the very technology I work on can best be defined within the relative horizons of expectation. And I think I like that because (and this is a somewhat tired maxim but hey, it still feels meaningful) it’s the stuff of being human. As Sartre said and as Heidegger said before him, we are beings for whom existence precedes essence. There is no model of me or you sitting up there in the Platonic realm of forms that gets realized as we live in the world. Our history is undefined, leading to all sorts of anxieties, worries, fears, pain, suffering, all of it, and all this suffering also leads the the attendant feelings of joy, excitement, wonder (scratch that, as I think wonder is aligned with perception), and then we look back on what we’ve lived and the essence we’ve become and it feels so rich because it’s us. Each of us Molly Bloom, able to say yes yes and think back on Algeciras, not necessarily because Leo is the catch of the century, but because it’s with him that we’ve spent the last 20 years of our lives.
The image is Paul Klee’s Angelus Novus, which Walter Benjamin described as “an angel looking as though he is about to move away from something he is fixedly contemplating,” an angel looking back at the chain of history piling ruin upon ruin as the storm of progress hurls him into the future.