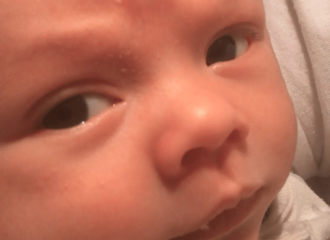
As I lifted my son Felix up over my shoulder for his standard burping stint after our midnight feed last Friday evening, he started to cough. I paused: normally he would burp, maybe spit, and the limit have some milk dripping out of his nostril. But he didn’t cough. I listened to him after placing him back in his bassinet, worrying there was something off. His breathing rattled raucous. I barely slept. A few hours later, at our 3:00 am feed, he coughed again. I alerted my husband that I worried something was wrong. We waited until morning. Normally, Felix is massively alert from about 9:00 am to 10:30 am. He plays Japanese war history with his father as I make breakfast for the two of us. But on Saturday he was lethargic. We tried to rouse him, but he stayed asleep. I called our midwife, called the family doctor’s office, called the resident on call at the hospital. By the time they responded, we had made a decision to bring him to the emergency room. He didn’t open his eyes while I put on his blue bear suit on the changing table, to keep him warm in the cold April wind outside. It was all I could do to stop my own tears, to maintain composure as the fear set in.
I projected a future state where all I had of him were the few pictures I’d put up on Facebook. Where all we were given was 5.5 weeks. Where all that would remain would be the memories of how active his breathing became when he concentrated, of the way he laid his head on his hands to sleep on my chest after a feed. I cried over this feared future and realized just how deeply I love him.
The parking lot at the hospital was surprisingly empty. Back during our prenatal visits in January and February we had to fight for parking spots, adding an additional 15 minutes travel time to make sure we were on time. We skipped the parking fee to save time and walked as quickly as possible to the hospital entrance. In front of the normal revolving door stood two temporary entrances: one for patients and visitors and one for staff. We walked through the first. The light changed from sun to dark. A few masked hospital attendants were seated at a greeting table. Upon seeing a small infant wrapped in my arms, hearing my cry that our son wouldn’t rouse, they rushed us to a screening from in the ER. We sanitized our hands and put on face masks. Walked through the bottom foyer spotted with a few people, some ordering coffee from Second Cup, some sitting like sentinels in masks monitoring the surroundings. We moved fast. Walked to a nursing station where four of five nurses looked at my son. “He’s still pink,” they said. “That’s a good sign. But we can’t care for him here. You should take him across the street to SickKids.”
We turned. Back through the corridor and across the street. I did everything I could to keep his head warm from the wind. Mihnea, my partner, reminded me it was more important to keep his airways open at this time. Our pupils resettled again as we entered the SickKids entrance. My glasses fogged from the humidity rising from my mouth through the mask. “I can’t see anything,” I said to Mihnea. He took off my glasses and wiped them as I walked to the line to register our son for care. The attendant asked me three screening questions and checked boxes on a form: Have you traveled to a foreign country in the last 14 days? Do you have any of the following respiratory symptoms? “Only one support person is allowed in with the child.” I told Mihnea it was me. He said he would try to get water-only baby wipes while we were in the hospital. I barely said goodbye, rushing to get my son care.
They put a hospital band around his tiny wrist and again comforted me that things couldn’t be dire because his color was still ok. I described his symptoms, answered another screening questionnaire about my own respiratory symptoms. And we were escorted down the hall into room number 7, waiting for the nurse and doctor to arrive.
The nurse came first. He was calm as they took his vitals, lethargic from the illness. Heart and breathing were normal. No audible congestion in the lungs. No fever. We stripped him naked and weighed him: 4.69 kilos, or 10 pounds 5.4 ounces. He’d grown a ton since his weight dropped to 6 pounds 8 ounces during the early-day dip in the hospital, fed only on colostrum from breasts getting practice with breastfeeding. The nurse asked if I’d like to turn the overhead light down. “Sure,” I said, settling into the dim darkness, obsessively scanning the white bars of the hospital crib as I held my son in my arms waiting for the doctor to arrive. I asked if they had diapers and wipes, as he needed to be changed. No wipes, but they did offer 2 size 1 diapers. They were scented: I cringed, as I only allow my son to wear diapers that are pure. But there was no choice. We wiped him with a paper towel and little water, leaving some residue on his bum. Again, this wasn’t the time for me to fuss.
The doctor came shortly thereafter. An Indian woman who exuded wisdom, practice, and care. She asked questions, listened to the rasp in Felix’s breathing as I rocked him, waited a little until she could hear a cough. Was encouraged that his vital signs were ok, and requested that I stay in the hospital through a couple of feeds to monitor how things progress. “It’s tricky with little ones,” she said. “If you’re worried, we’re worried. Symptoms progress rapidly in one or the other direction, so let’s watch him and see what happens.”
“Ok,” I responded, laconic. “Do you have any food or water for me while I wait?” I am meticulous about my hydration and nutrition while breastfeeding my son. Drink liters of water per day. Eat incredibly well.
“I can bring you a cup of water and a nutrigrain bar. If you need a proper meal, we can see to that later.”
She returned with a small styrofoam cup filled with tap water, 2 nutrigrain bars (one blueberry and one mixed berries), and 2 packets of shortbread cookies. I asked if she could watch Felix while I went to the bathroom. She offered to hold him, cradling him against the yellow gown over her chest.
She passed him to me and closed the curtain behind her as she left. I downed the 6 ounces of water from the styrofoam cup and plugged in my cell phone. And I sat in a hunter green plastic chair, holding my son. They’d removed the comfy nursing chairs because they are harder to sterilize during COVID.
Hours passed. I looked at the white bars on the hospital crib. Paced around the room to relieve my aching back. Held my son. Was bothered by the sickly smell of the scented diaper. Spoke to Mihnea and my parents on the phone. Responded to a few texts I’d been meaning to respond to, mentioning to an old friend that we were in the ER. Nothing to read. Nothing to eat. I was in my pyjamas, as I didn’t make time to change before we left: grey Quantas airline sweatpants my mother got on a trip back in the 1990s, the drawstring still in the pants under tatters of revealed seams; Mihnea’s grey Burberry shirt with four buttons near the collar, undone so I could feed; no bra; hiking boots; a grey sweatshirt stained with spit up and leaking breast milk I took off and laid on the green plastic chair next to me so Felix wouldn’t get wet. We didn’t have any extra outfits for him. Nothing. I needed to keep him dry.
Eventually, he ate. It was a tired feed, lacking his normal vigor. He sneezed and coughed, but didn’t pull off. I took videos of his sounds to show the doctor.
She returned to check in a few times and eventually we did another examination. And, fortunately, he stirred. “Look at his eyes!,” she exclaimed. “He is beautiful. Strange that the first images he’ll form will be of people will be with masks.”
She was encouraged by his energy, but offered a COVID swab. I accepted. The nurse came in with what looked like a small white sword, the size of a cocktail umbrella. While Felix had roused a little, he was still drowsy so more tolerant of sticking a swab up his nose than he normally would be. I embraced him. She stuck it up the right nostril. He cried a little, but not too badly. She stuck it up the left. And that was it. “Can I hurt him?” I asked. “No,” she replied. “You’ll have results in 2-4 days.”
Because Felix was showing signs of improvement, the doctor felt comfortable discharging us around 5:00 pm, about 5 hours after we arrived. She diagnosed him with a viral respiratory infection and gave instructions on waiting for the COVID test result. Made a virtual check-in with a pediatrician the following day. “Are there any concerns I can help address?” she asked.
“My biggest worry is that I will lose my son,” I replied.
“We’ll act on him before that happens. Put him on an IV or oxygen support. What matters is that if you’re worried, we are worried. Symptoms with little ones progress quickly, and you know better than anyone if he is behaving differently from normal. Look out for signs of breathing distress, fever, dehydration, vomiting. But some congestion is ok. Good luck!”
I dressed Felix back in his big, warm, blue bear suit. Mihnea came and picked us up, holding Felix closely to his chest as we greeted us at the entrance where he’d left us that morning.
We drove home, vigilant. We ate dinner, vigilant. We slept next to him in our bed, vigilant. We fed him, vigilant.
He got better. Quickly.
We got a call within 20 hours informing us that his COVID test results were negative, but that, given the potential for a false negative, he should still be isolated for 3-4 days. We wouldn’t have brought him for a walk in the cold anyway. Homebound, vigilant.
The experience upended us. We learned to cherish his wails, as they signaled vigor and life. To cherish the frustrations of being tired as he still doesn’t sleep more than 3 hours at a time at night (but it’s getting better and better!). To cherish his clear breathing. To cherish the raw fact of his existence. To cherish that he is our son. We always did, but we do now more than ever.
There is no science to newborn care. It’s a matter of intuition. States change in a matter of hours, and a parent is tasked with watching severity, not duration. I wanted guidelines, measurements, answers. There were none. Just the amazing burden of responsibility to know another deeply, to know Felix inside out and backwards and know when it could be time to bring him back to the hospital for additional care.
It’s as I mentioned in my last post: a recipe for misery is to compare your child with statistical development milestones. Parenting is about depth of knowledge, the depth of knowing one little person in every aspect of their being. I have deepened my knowledge of the rate and cadence of his breathing. Of his body temperature. Of his moods. Of the hint of redness that appears around his eyes when he is sick. Of the wetness of his tears and the inside of his mouth. Of the way his hands move when he is curious and when he is scared. Of the feelings that emerge in the bath, on the bed, on his play mat. He is my world now. Our world. The only way to care for a sick newborn is to pay close attention to who he is and how he is. And to know when he’s not himself.
I will hold deep inside me a token of unconditional love in the backache I felt sitting in the dark against a plastic green chair in a hospital room on a Saturday afternoon. There was no question I would do otherwise, as I will when, inevitably, the next worry comes our way.
The featured image isof my son Felix this Saturday morning. I can see the illness in the little tear grazing the bottom of his eye, the depth and sadness in his plea. He couldn’t voice his pain, couldn’t tell us what was coming. All we could do was listen.
Time to write is sparse and passes with a 10-pound being breathing warmly on my chest. Too sparse to bother with hypotaxis and refined style. As such, I present but a list of the things I’ve learned in the past 5 weeks since my son Felix was born. Some of these lessons feel universal; others are undoubtedly conditioned by the particulars of the world in March and April, 2020, this bizarre counterworld of the Coronavirus quarantine.
Reflections
It is a bad idea to get a dog before having a baby. Daft and pacified by pregnancy hormones, I thought that would bring joy earlier this year. Visions of my domestic paradise. Thank god my partner was wise enough to think otherwise.
Footed onesie pajamas should have zippers. It’s ludicrous that they make pajamas with snaps. Way too hard to get onto a newborn who screams crying when changed in the early weeks of his life. Every new mother should know this.
Birthdays with a newborn during quarantine are humble, just like any other day. The highlight of my birthday was a walk alone with my partner while my parents watched the baby. We ate chicken soup for dinner because my partner had stomach issues to heal. A birthday with a newborn indexes the complete toppling of priorities from self to other: it’s for him that I want presents now. No need for anything else.
Towards the end of my pregnancy I discovered that touch is a more fundamental medium of communication than language. Now, in the first month of my son’s ex-utero life, I’ve learned the importance of music and movement. I have sung and danced more in 5 weeks than in the last 5 years or more. Perhaps than in my entire life. I sing Felix to sleep after a 3:00 am feed, rocking back and forth to Tchaikovsky’s Sleeping Beauty to ease the spit up that prevents his sleep. I improvise melodies, finding a Phillip Glass- or Max Richter-like motif I can repeat over and over and over in harmony with my rocking squats to calm my son. He loves Bach, Mozart, Gould playing Bach, Sokolov playing Bach, Sokolov playing Schubert. He heard his father play piano every morning in my womb for nine months, and it is his home.
You learn how to do nothing. You watch him feed, watch how his eyes look out into space with a keen curiosity as he coos. Watch how his hands gradually open up as his stomach fills. You learn to accept that tasks won’t get done. You’ll start to assemble his play gym and he’ll wake up crying and you have to stop and leave the task partially complete and attend to it later. Your friend Marion mentioned that you have to love the process, not the outcome. That outcomes-focused thinking, the drive of hitting OKRs that drives life in business, is toxic to the unruly spirit who has no need for goals. He needs love, care, unconditional attention. Your sense of accomplishment is overhauled, replaced with the solid awareness that he is gaining weight well, thriving, healthy as can be. That it would be devastating if it were otherwise.
And yet, you also learn how to prioritize better and differently than before. You fit a load of laundry into your morning routine, taking advantage of the few spare minutes while your partner cares for your child. You make the transitions fast: out for a run now, don’t bother with the fussing, if you don’t go, you won’t get it in. You settle for short distances, as your postpartum body is still healing. You feel a sense of accomplishment when you realize you can do the laundry and cook a wholesome meal and even write a blog post with your baby.
You see the beauty in the little things, effortlessly seeping into the holiness of everyday life that somehow felt like play acting before, somehow felt like something to strive towards and that is now a given, a ground you walk on. The heat of shower water over your shoulders, as your back muscles release from the new strain. The light reflecting off the painting in the piano room, that’s been there evening after evening but only noticed now that your son gazes upon it from his 4Moms swing during dinner time. The magenta inlay in the painting Bruce Jefferson gave that hangs in the nursing room, which you discovered watching your son watch it. The etching of the tree branches against the evening sky. The feel of the wind on your cheeks. The taste of carrot juice in the morning. The fluffiness of the duvet when you get in for the third time in one night. The details of the world sing. There is no longer a world outside distracting you from noticing them.
The baby loves to look at the new world. His eyes are keen and curious. He loves to look at the rafters that line the ceiling in the basement. Loves to look at the back porch after dinner. It’s the best way to soothe him at the cusp of the witching hour.
One way for a new mother to make herself miserable and strip the joy from raising a newborn is to read the internet and compare her child’s development to what’s expected at certain ages. She starts to see her child against the backdrop of a statistical norm, blinds herself from seeing him, uniquely, seeing the wonders of his personal journey and development. Fatigue cuts the integral into a derivative: each green poop, each subtle variation from the perfectly healthy baby catalyzes massive anxiety. But wait a few hours and the pendulum shifts back to normal. And if I stay off the damn internet, I see him for who he is, grow with him, respond to what he’s telling me rather than imposing external methods and guidelines onto him. For we are one, both one and not one, a unit that emerges from our interaction. He is calmer when he senses authentic interaction between my partner and me. He feels it’s right. We supervene on one another. Therein lies the joy.
Beauty is not the same as joy. There are moments of sublime beauty as I observe the curvature of his closed eyes, the color of his skin, olive like his father’s, against my chest. My son, for me, is more a bundle of beauty than of joy. There are joyful moments but not when I force Mom voice upon him to get to a smile faster. Our joy cannot be feigned.
Fatigue is not depression. It can feel that way, but it’s just fatigue. It plays nasty tricks upon the mind and has a funny way of making us regress back to the most shameful inlets of our selves. But it’s just fatigue.
The body adapts more easily to punctuated sleep cycles than I ever expected. Feed for 30 minutes, keep him upright for 20 minutes, fighting off sleep, slowly, slowly, transfer him to his bassinet, wait, deep breath, hoping he’ll stay asleep, hop into bed, wake up in 45 minutes, 60 minutes, 90 minutes, 120 minutes, longer stretches as nights advance, feed again. And the key is to just lie there and let the images wash over the mind and let sleep come. For it comes. It has no choice.
Face masks strip us of emotional entanglement with other beings, a core emotional and spiritual dimension of our humanity. When a new mother gets a runny nose in normal times, she may wash her hands more frequently and make sure she sneezes into tissues, but only a few are paranoid enough to put on a face mask. But the age of COVID-19 wants otherwise. Having a sore throat and runny nose is means for panic, panic, fear something could happen to him, even if infants are reputed to be more immune. But it is torture to wear a face mask while breastfeeding, as the mother is deprived of her ability to look upon her son. All she sees is blue, a blue curtain blocking their connection. He cries, and she cannot console him. She cannot read his cues. She is isolated, apart. The dilemma is heartbreaking. But time helps wash away the pain.
6 feet doesn’t feel like enough on walks. 9 feet. Walking in the middle of the road, nearly getting hit by cars, to avoid runners and walkers and dogs. Fear and anxiety lace time outside, time that would otherwise capture the joy of seeing him at ease in the fresh air, hearing the coos from the carrier on my chest, on my partner’s chest. Someday. Someday we will go for long walks and love the sun and greet people without fear they will harm us or we will harm them.
The underpinning social mechanisms of different companies are revealing themselves clearly, showing differences that weren’t as apparent before COVID. Netflix, Amazon, and Zoom are tuned for an isolated, separated society. Facebook too, absent the advertising business model. These companies thrive on distance, thrive on people staying at home away from one another. WeWork, AirBnB, Uber, the sharing economy companies, represent a fundamentally different concept of social engagement, one where people share spaces, share belongings, come together across the digital divide. Is the distributed, isolated world enabled only by companies like Amazon the political infrastructure of our future world? Will the nation as political unifier surrender to this new kind space? Will we somehow come back to normal or will the civilization my son grows up in look different from that I grew up in, from 1984 to 2020? What can I do to influence his world? What should I do? For now, our world is small, contained, insular. A sleeping boy on my chest as I write, listening to Glenn Gould, the master isolationist, playing Mozart piano sonatas.
The featured image of me and my son Felix. We looked more or less like this while I wrote this post.
Touch is the most basic, the most non-conceptual form of communication that we have. In touch there are no language barriers; anything that can walk, fly, creep, crawl, or swim already speaks it. - Ina May Gaskin, Spiritual Midwifery
Sometimes we come into knowledge through curiosity. Sometimes through imposed convention, as with skills learned during a course of study. Other times knowledge comes into us through experience. We don’t seek. The experience happens to us, puzzling us, challenging our assumptions, inciting us to think about subject we wouldn’t have otherwise thought much about. That this knowledge comes upon us without our seeking enforces a sense that it must be important. Often it lies dormant, waiting to come to life. [1]
I have never thought deeply about how and what we communicate through touch. I’ve certainly felt the grounding power of certain yoga teachers’ hands as they rubbed my temples and forehead during savasana. I’ve been attuned to how the pressure of a hug from a girlfriend in high school signaled genuine affection or a distancing disgust, the falseness of their gesture signaled through limp hands just barely grazing a fall jacket. When placing my hand on the shoulder of someone who reports to me at work, preparing to share positive feedback on a particular behavior, I’ve consciously modulated the pressure of my hand from gentle to firm, both so as not to startle them away from their computer and to reinforce the instance of feedback. Most of my thinking about communication, however, has hovered in the realm of representation and epistemology, trapped within the tradition that Richard Rorty calls the Mirror of Nature, where we work to train the mind to make accurate representations of the external world. Spending the last five years working in machine learning has largely reinforced this stance: I was curious to understand how learned mathematical models correlated features in images with output labels that name things, curious to understand the meaning-making methods of machines, and what these meaning-making methods might reveal about our own language and communication.
And then I got pregnant. And my son Felix grew inside me, continues to grow inside me, inching closer to his birth day (38 weeks and counting). And while, like many contemporary mothers-to-be, I initially watched to see if he responded differently to different kinds of music, moving more to the Bach Italian Concerto or a song by Churches or Grimes, while I was initially interested in how he would learn the unique intonations of his mother and father’s voice, my experience of interacting with Felix changed my focus from sound to touch. My unborn son and I communicate with our hands and feet. The surest way to inspire him to move is to rub my abdomen. The only way he can tell me to change a position he doesn’t like is to punch me as hard as he can. Expecting mothers rub their bellies for a reason: it’s an instinctual means of communicating, transforming one’s own body into the baby’s back, practicing the gentle, circular motions that will calm the baby outside the womb. Somehow it took the medical field until 2015 to conduct a study concluding that babies respond more to a mother’s touch than her voice. I can’t help but see this is the blindspot of a culture that considers touch a second-class sense, valued lower than the ocular or even auricular.
But as research in artificial intelligence and robotics progresses, touch may reclaim a higher rank in the hierarchy of the senses. Brute force deep learning (brute force meaning throwing tons of data at an algorithm and training using gradient descent) has made great strides on vision, language, and time series prediction tasks over the past ten years, threatening established professional hierarchies that compensate work like accounting, law, or banking higher than professions like nursing or teaching (as bedside manner and emotional intelligence is way more complex than repetitive calculation). We still, however, have work to do to make robots that gracefully move through the physical world, let alone do something that seems as easy as pouring milk into our morning cereal or tying our shoes. Haptics (the subfield of technology focused on creating touch using motion, vibration, or force) researcher Katherine Kuchenbecker puts it well in Adam Gopnik’s 2016 New Yorker article about touch:
Haptic intelligence is vital to human intelligence…we’re just so smart with it that we don’t know it yet. It’s actually much harder to make a chess piece move correctly-to pick up the piece and move it across the board and put it down properly-than it is to make the right chess move…Machines are good at finding the next move, but moving in the world still baffles them.
And there’s more intelligence to touch than just picking things up and moving them in space. Touch encodes social meaning and hierarchy. It can communicate emotions like desire and love when words aren’t enough to express feelings. It can heal and hurt. Perhaps it’s so hard to describe and model haptic intelligence because it develops so early that it’s hard for us to get underneath it and describe it, hard to recover the process of discovery. Let’s try.
Touch: Space, Time, and the Relational Self
Touch is the only sense that is reflexive.[2] Sure, we can see our hands as we type and smell our armpits and taste the salt in our sweat and hear how strange our voice sounds on a recording, but there’s a distance between the body part doing the sensing and the body part/fluid being sensed. Only with touch can we place the pad of our right pointer finger on the pad of our left pointer finger and wonder which finger is touching (active) and which finger is being touched (passive). The same goes if we touch our forearm or belly button or the right quadricep just above the knee, we’re just so habituated to our hands being the tool that touches that we assume the finger is active and the other body part is passive.
Condillac’s statue in the Traité des Sensations has always reminded me of the myth of Pygmalion, who falls in love with a statue he creates (inspiring what would become My Fair Lady). Here’s Rodin’s take on the myth.
In his 1754 Traité des sensations[3], the French Enlightenment philosopher Étienne Bonnot de Condillac went so far as to claim that the reflexivity of touch is the foundation of the self. Condillac was still hampered by the remnants of a Cartesian metaphysics that considered there to be two separate substances: physical material (including our bodies) and mental material (minds and souls). But he was also steeped in the Enlightenment Empiricism tradition that wanted to ground knowledge about the world through the senses (toppling the inheritance of a priori truths we are born with). The combination of his substance dualism (mind versus body) and sensory empiricism results in a fascinating passage in the Traité where a statue, lacking all senses except touch, comes to discover that different parts of her body belong to the same contiguous self. The crux of Condillac’s challenge starts with his remark that corporeal sensations can be so intertwined with our sense of self that they are more like “manners of being of the soul” than sensations localized in a particular body part. The statue needs more to recognize the elision between her corporeal and mental self. So Condillac goes on to say that solid objects cannot occupy the same space: “impenetrability is a property of all bodies; many cannot occupy the same space; each excludes the others from the space it occupies.” When two parts of the body come in contact with one another, they hit resistance because they cannot occupy the same spot. The statue would therefore notice that the finger and the belly are two, different, mutually exclusive parts of space. At the same time, however, she’d sense that she was present in both the finger and the belly. For Condillac, it’s this the combination of difference and sameness that constitutes the self-reflexive sense of self. And this sensation will only be reinforced when she then touches something outside herself and notices that it doesn’t touch back.
For Condillac touch unifies the self in space. But touch can also unify the self in time. When I struggled sleep as a child, my mother would stroke my hair to calm me down and help me find sleep. The movement of her hand from temple to crown had a particular speed and pressure that my brain encoded as palliative. When I receive a similar touch today, the response is deep, instant, so deep it transcends time and brings back the security I felt as a child. But not merely security: the transition from anxiety to security, where the abrupt change in state is even more powerful. Mihnea, father to the unborn child growing inside me, knew this touch before we met. I didn’t need to ask him, didn’t need to provide feedback on how he might improve it better to soothe me. It was in him, as if it were he who was present when I couldn’t sleep as child. And not in some sick Freudian way — I don’t love him because he harkens memories of my mother. It’s rather that, early in our relationship, I felt shocked into love for him because his touch was so familiar, as if he had been there with me throughout my life. The wormhole his hand opened wasn’t quite Proustian. It wasn’t a portal to bring back scenes form childhood that lay dormant, ready to be relived (or, as Proust specifies, created, rather than recovered). It was more like a black hole, collapsing my life into the density of Mihnea’s touch, telling me he would father our children and know how to help them sleep when they were anxious.
There’s an implicit assumption guiding the accounts of Condillac and Mihnea’s touch: that, to use Adam Gopnik’s words, “we are alive in relation to some imagined inner self, the homunculus in our heads.” But touch becomes even more interesting when it helps us understand “consciousness itself as ‘exteriorized’, [where] we are alive in relation to others…[where] our experience of our bodies-the things they feel, the moves they make, and the textures and people they touch-is our primary experience of our minds.” Here Gopnik describes the thinking of Greater Good Science Center founding director Dacher Keltner, who (I think, based upon the little I know…) disagrees the Kantian tradition that morality is grounded in reason and self-imposed laws and instead grounds morality in the touch that begins with the skin-to-skin contact between mother and child.
A cursory introduction to psychologist Dacher Keltner’s thinking about touch.
I think the magic here lies in how responsive touch can or even must be to be effective communication. Touch seems to be grounded on experimentation and feedback. We imagine what the person we are about to touch will sense when we place our hand upon their arm, perhaps even test the pressure and speed of our movements on our own forearms before trying it out on them. And then we respond, adapt, feel how their arms encounter our fingers and palms, watch how their eyes betray what any emotions our touch elicits in them, listen for barely audible sounds that indicate pleasure or security or contentment or desire or disgust. Touch seems to require more attention to the response of the other than verbal communication. We might (albeit often incorrectly) presume we’ve transmitted a message or communicated some thought to others when we say something to them. It’s better when we watch how they respond, whether they have captured what we mean to say, but so often we’re more focused on ourselves than the other to whom we seek to communicate. This solipsism doesn’t pass with touch. Our hands have to listen. And when they do, the effect can be electric. The one being touched feels attended to in a way that can go beyond verbal and cognitive understanding. Here’s how Ina May Gaskin described an encounter with a master of touch, a capuchin monkey:
She took hold of my finger in her hand-it was a slender, long-fingered hand, hairy on the back with a smooth black palm-and I had never been touched like that before. Her touch was incredibly alive and electric…I knew that my hand, and everyone else’s too, was potentially that powerful and sensitive, but that most people think so much and are so unconscious of their whole range of sensory perceptors and receptors that their touch feels blank compared to what it would feel like if their awareness was one hundred percent. I call this “original touch” because it’s something that everybody as a brand new baby, it’s part of the tool kit…Many of us lose our “original touch” as we interact with our fellow beings in fast or shallow manner.
Gaskin goes even further than Keltner in considering touch to be the foundation of morality. For her, touch is the midwife’s equivalent of the monk’s mind, and the midwife should take spiritual vows and abide by spiritual practices to “keep herself in a state of grace” required to tap into the holiness of birth. In either case, touch topples an interior, homunculus notion of self. The power lies in giving ourselves over to our senses, being attuned to others and their senses. Being as present as a capuchin monkey.
Haptics: Extending the Boundaries of the Self
This focus on presence, of getting back to our mammalian roots, may strike some readers as parochial. We’re past that, have evolved into the age of digital communication, where, like the disembodied Samantha from Spike Jonze’s Her, we can entertain intellectual orgies with thousands of machine minds instantaneously, no longer burdened by the shackles of a self confined to a material body in space. The haptics research community considers our current communication predicament to be paradoxical, where the very systems designed to bring us closer together end up leaving us empty, fragmented, distracted, and in need of the naturalness of touch. So Karon Maclean (primary author), a prominent researcher in the field:
Today’s technology has created a paradox for human communication. Slicing through the barrier of physical distances, it brings us closer together-but at the same time, it insulates us from the real world to an extent that physicality has come to feel unnatural…Instant messaging, emails, cell phones, and shared remote environments help to establish a fast, always-on link among communities and between individuals…On the other hand, technology dilutes our connection with the tangible material world. Typing on a computer keyboard is not as natural as writing with a nice pen. Talking to a loved one over the phone does not replace a warm hug.
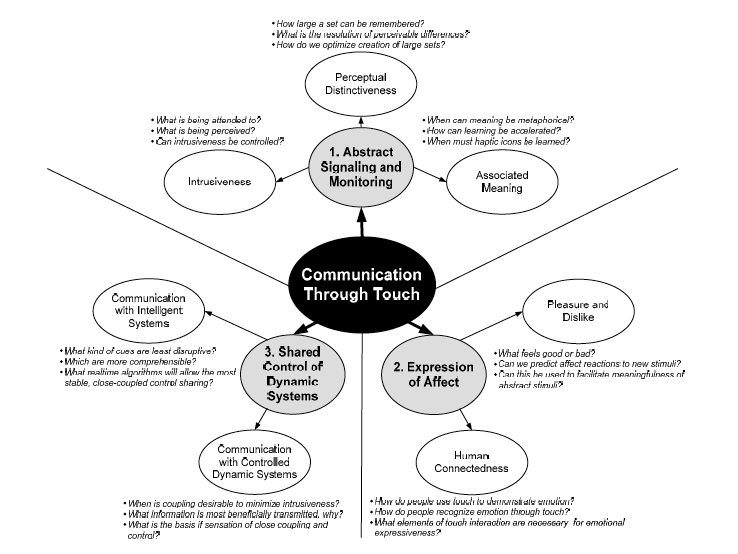
An image summarizing Karon Maclean et al’s research interests in haptic intelligence, from their article “Building a Haptic Language: Communication Through Touch”
Grounding research in concrete case studies centered around the persona of a traveling sales woman named Tamara, Maclean and her co-authors go on to describe a few potential systems that can communicate emotions, states of being, and communicative intention through touch. One example uses a series of quickening vibrations on a mobile phone to mimic an anxious heart rate, signaling to Tamara that something is wrong with her son. Tamara can use this as an advanced warning to check her text messages and learn that her 5-year-old son is in the hospital after cutting himself on a rusty nail. In another example, Tamara sends a vibrating signal to a mansplaining colleague who won’t let her get a word in edgewise. The physical signals don’t require the same social awkwardness that would be required to cut off a colleague with a speech act, but end up leading to more collaborative professional communication.
Maclean is but one researcher among many working on creating sensations of touch at a distance. My personal favorite is long-distance Swedish massage to feel more closely connected with a partner. Students in Katherine Kuchenbecker’s research lab at the Max Planck Institute have published many papers over the last couple of years focusing on generating a remote sense of touch for robot-assisted surgery, to make the process feel more present and real for a human surgeon operating at a distance. Other areas of focus for haptics research are on prosthetics. Gopnik’s article is a good place for layman interested in the topic to start. I found the most interesting conclusions from the work to be how sensory input needs to be manipulated to be cognizable as touch. Raw input may just come off as a tingle, a simulated nerve sensation in an artificial limb; it needs modification to become a sensation of pressure or texture. All in all, the field has advanced a long way from the vibrations gaming companies put into hand-held controllers to simulate the experience of an explosion, but it still has a long way to go.
Let’s imagine that, sometime soon, we will have a natural, deep sense of touch at a distance, with the same ease that today we can send slack messages to colleagues working across the globe. Would we feel ubiquitous? Would our consciousness extend beyond the limitations of our physical bodies in a way deeper and more profound that what’s available with the visual and auditory features that govern our digital experience today? Will we be able to recover our “original touch” at a distance, knowing the Jerónimos Monastery in Lisbon more intimately because we can feel the harsh surface of its Lioz pillars, can sense, through the roughness of its texture, the electric remnants of the fossils that gird its core?
I just don’t think anything can replace the sanctity of our presence. The warmth and smell and stickiness of a newborn baby on our skin. The improbable wonder of a body working to defy entropy, if only for the short while of an average human lifespan. This doesn’t mean that the tapping into the technology of touch isn’t worthwhile. But it does mean that we can’t do so at the expense of losing the holiness of a different means of extending beyond the self through the immediate connections to another. At the expense of not learning from the steady rhythm of kicks and squirms that live within me, and will soon come to join us in our breathing world.
Arches from the Jerónimos Monastery in Lisbon. I found myself drawn to touching the Lioz pillars when I was there, and was shocked at the abrasiveness of their texture.
[1] What I’m trying to get at is different from the sociological concept of Verstehen, a kind of deep understanding that emerges from first-person experience. There’s definitely a part of this kind of knowledge that is grounded in having the experience, versus understanding something theoretically or at a distance. But the key is that the discovery of the insight wouldn’t have come to pass without the experience. I am writing this post - I have become so interested in touch - because of the surprising things I’ve come to learn during pregnancy. Without the pregnancy, I’m not sure I would have been interested in this topic.
[2] I think this is accurate, but would welcome if someone showed the contrary.
[3] This is one of my favorite texts in the history of philosophy. I also referenced it in Three Takes on Consciousness.
The featured image is a detail from Bernini’s Rape of Proserpina, housed in the Galleria Borghese in Rome. Bernini was only 23 years old when he completed the work. Proserpina, also known as Persephone, was the daughter of Demeter, the goddess of harvest and agriculture. Hades loved Proserpina, and Zeus permitted him to abduct her down to the underworld. Demeter was so saddened by the disappearance of her daughter that she neglected to care for the land, leading to people’s starvation. Zeus later responds to the hungering people’s pleas by making a new deal with Hades to release Proserpina back to the normal world; before doing so, however, Hades tricks her into eating pomegranates. Having tasted the fruit of the underworld, she is doomed to return there each year, signaling the winter months when the harvest goes limp. The expressiveness of Hades’ fingers digging into Proserpina’s thigh illustrates the complexity of touch: her resistance and fear shout from creases of marble muscles, fat, and skin. And somehow Bernini’s own touch managed to foster the emotionality of myth in marble, to etch it there, capturing the fleeting violence of rape and abduction for eternity.
A literary experiment in the style of the first two volumes of Karl Ove Knausgaard’s Seasons Quartet. As Knausgaard wrote Autumn and Winter waiting for his daughter Anne to be born, so I write this post waiting for my son Felix, who could come any day now.
Yesterday around 11:40 am Mihnea and I went to Big Wax car wash at Parliament and Front Street in Toronto. There was a medium-long line, but it wasn’t nearly as long as the one we left in exasperation the day before at an Esso automatic car wash closer to our home. There it seemed like everyone in Toronto washed their car at the same place and at the same time on a Saturday afternoon. Urban rituals, tucked into life like the starched collared shirts that pixelate the PATH conjoining the Toronto banks with prepared foods from McEwan’s restaurants and grocery stores. The line at Big Wax moved fast because the car wash staff moved fast. The process started with a man who walked car by car to take people’s orders in intermittent lulls from his primary work spraying down cars before the main wash. His thick brown eyebrows furrowed under brown hair and eyes in discipline, his gaze never landing anywhere but remaining aloof, absent, focused, leaving just enough space to take in the eccentricities and emotionality of the clientele like a data stream, but never stopping long enough to absorb them. On his carbonless copy paper pad, he checked off whether the customer wanted an $11.75 Rinse and Dry or a $14.95 Rinse and Shine or a $26.00 Big Wax complete job, the whole works, including interior cleaning. Didn’t chit chat. Checked the box, placed the yellow sheet on the dashboard and handed the white sheet for payment to Mihnea, moved on to the next car, eventually pivoted back to the front of the line to spray the next car and keep things moving. We inched our way to the front of the line. Our wheels were cockeyed and another staff member gestured vigorously through the closed windows to get us to move them straight so they would settle into the ruts that would pull the car through the wash. Inside the car we shuffled through my Spotify Discover Weekly, largely disappointed by the recommended music. Most of my time listening to music is spent at work, and most of the work music does for me is to block out the noise of the open concept office spaces I inhabit so I can concentrate. I favor minimal ambient music like Brian Eno’s Thursday Afternoon or any track on Jónsi’s Riceboy Sleeps or Max Richter’s Recomposed by Max Richter: Vivaldi’s Four Seasons or other Scandinavian and Icelandic minimalist and post-rock composers like Ólafur Arnalds and Jóhann Jóhannsson and Arvo Pärt (admittedly somewhat different). Too much melodic structure distracts me; words distract me; but the rich symphonic interplay of minimalist rhythms and melodies keeps me cradled, protected, focused even when others bang keys or eat carrots or speak about something I’d have to pretend not to want to overhear. The problem is that the latent representation guiding the Spotify recommender system frequently mistakes my taste in minimalist ambient music for a taste in massage-table easy-listening piano music. This week’s recommendations largely sucked. I pressed the “don’t like this song” icon again and again, cycling exasperation until we landed into a rich tapestry of a Jónsi song as we put the car into neutral to begin our journey in the underworld of the automatic car wash.
Going through a car wash is like being in a whale’s stomach, or being on a roller coaster in a broken-down amusement park in North Korea. All control over the vehicle and experience is handed over to the rails of the machine, which lugs the car in incremental steps. Soapy water gushes around the windshield like saliva, bright red tongues lash and lap suds as if they were breaking down prey flesh. The tongues thud against the steel and glass of the car, not so hard that it’s worrisome but hard enough that it’s a distinctive thud. After red comes blue as the light dims in the center of the wash’s belly. The cadence of swishing and swooshing changes as salt and mud and dirt and winter muck falls off the car onto the ground below, in through ducks into the ground. The car moves on to the next station. Felt fabric organs close in once more over the windshield. Inside the car is warm and dry. Eyes watch awestruck, ears hear the nuances between each phase. Light emerges again near the exit and a massive dryer descends from the ceiling, its air spewing water droplets from the windshield with a force much greater than the hand dryers in public bathrooms, but similar. If the dryer were to have direct contact with faces inside the car, lips would stretch like a skydivers. The whole thing lasts about five minutes.
The experience of the car wash hasn’t changed at all since I was a kid. When I was in elementary school, we lived on Highland Drive in Apalachin, New York, and would go to the car wash every few weeks just past Hidy Ochiai’s Karate studio on the Vestal Parkway. I wanted to go, loved going, and suspect my brother did too. It’s easy to understand why the car wash would be such a treat: the experience is radical, bizarre, otherworldly. In my memory we pulled up to an automated menu similar to the interface at a fast food drive-in. I don’t think, in reality, the car wash menu visual design was anything like images of a Big Mac or Chicken McNuggets. It was probably a simple pick list in primary colors like Mihnea and I saw yesterday at Big Wax. I suspect my memory tricks me because the drive-thru feels similar to the car wash; we wait in the car for a service, and select from a menu along the way. I haven’t eaten drive-thru food since I was a kid. And I believe yesterday was the first time I went through an automatic car wash since we lived in Apalachin. Part of me thinks that can’t be true, that I must have experienced a car wash during my teens in the Boston suburbs. I didn’t own a car for much of my adult life, as I lived in urban downtown cores and moved around using public transportation (and barely cared for the busted Suzuki Forenza I drove around the Bay Area during graduate school; at any rate, cars rarely need washing in Palo Alto). But it’s also possible that yesterday my mood and mindset was open and imaginative enough to elide more with the joy I experienced at the car wash as a child. That the harmonic overtones the experience evoked took me back to the car wash experience of my 7- or 8-year-old self, absorbed in the oddity, not distracted by the self-absorbed tribulations of my 14- or 15-year-old self. Perhaps.
Images from the homepage of Hidy Ochiai’s Karate Studio in Vestal, New York. My brother and my dad took karate lessons there when I was a kid; my brother was 3 years younger than I. I remember Hidy could walk up walls and do flips to get back to steady ground.
In late November, on our way home from the ritualistic Thanksgiving trip to my aunt’s house in Scranton, Pennsylvania, Mihnea and I stopped in Apalachin so I could show him the house I grew up in. Here it is, at the corner of Highland Drive and Alpine Drive.
It hasn’t changed drastically, although there are differences. I don’t think we ever had a yellow door. We used to have a big crab apple tree in the front yard and a willow tree on the side near the two windows visible in the photo near the chimney. Those were windows into my childhood bedroom, and I spoke to the willow tree like a friend until we tore it down in the wake of a hurricane. When we visited in November, I stood on the driveway and looked up the street. It felt the same. I could see the Valentas’ house and see the Batman Boomerang I once accidentally threw into a friend’s forehead. I looked down the street and it felt different. The Yonkos’ home seemed to sit at a different angle than I remembered, the proportions were off. I could see my brother getting hives from eating huckleberries at the house across from the Yonkos’ down the road. Mihnea and I walked up the hill and down another hill to Tioga Hills Elementary School. The walk was shorter than I remembered from my childhood, when my hair tips used to freeze, still wet from the shower. We walked behind the school and, for the first time in 20 years, I remembered what it felt like to play wall ball with the boys, remembered feeling invited by them because I was athletic, but already embarrassed in budding self-awareness. As we looped around the front of the school, I remembered the day, in fifth grade, when I wore my new Limited cut off jean shorts and Limited bright pink and yellow sleeveless plaid shirt, which I wrapped up near my waist like an aerobics instructor in the early 90s. I was freezing, and one of my teachers asked me why I thought it was a sound idea to wear an outfit like that when it was still so cold. The forecast predicted 62 degrees fahrenheit; I was excited for the warmth of spring, but hadn’t yet realized a daily high could be but a moment in time. I don’t think I got sick, but I shivered most of the day. After seeing the house, Mihnea and I ate at the Blue Dolphin Diner, where we ate frequently when I was a child. They served the same homemade white bread loaves: square loafs that came with a serrated knife and little whipped butter packets. We sat at the bar. When I was a kid, we sat in the main dining room. I ate a Greek combo plate with moussaka and hot dolma and a greek salad with canned black olives and pepperoncini and iceberg lettuce. I could barely eat half before I was stuffed. Mihnea had a Ruben and crinkle-cut french fries. When I was a kid, I used to eat the baked ziti. My mother would warn that the man was coming if my brother and I acted up.
Yesterday, after the huge dryers blew most of the water off the car, we pulled up outside and two more staff members came to do the final hand dry with long, thin, light-blue towels. Mihnea got out to pay the bill, and I was alone inside listening to the one salvageable track from my Discover Weekly List. The guy drying the car asked me if he could come in a pull it forward to make more space for the next car. I said sure. Upon getting in and seeing my 36-week-pregnant belly underneath a sloppy grey sweatshirt he exclaimed “well look at you!” And he warmed up. Like many strangers do these days. Being pregnant is like being a dog: people smile at me and greet me and seem to presume innocence.
“Boy or girl?” he asked.
“Boy,” I replied.
“I have two. It’s going to change your life. But for the better. You will love it.”
I smiled. “I think so too.”
He finished his work and left the car. But my view of him and his view of me changed. It wasn’t just a transaction, wasn’t just aloof eyes pushing the cars through the car wash. I heard the brightness of his voice and knew slightly more about the facts of his existence, rather than speculating about his life outside the car wash. He had two boys. We shared something fundamental. I wonder if his boys think the car wash is as strange and magical as I do, as I suspect Felix will.
The featured image has nothing to do with a car wash, besides the metaphorical similarity of salt clinging on the sides of cars in winter like barnacles and shells clinging to metal fences near the lake. The mood of the image better matched the mood and tone of the piece than any images I could find of automatic car wash brushes.
You and I are one. Both one body and not one body. Our two hearts beat together, yours relying on the pulse of the chord that nourishes you, gives you oxygen, gives you amniotic food. You eat what I eat. Feel shadows of what I feel. How your brain develops depends on what I feel, as I hint what you will face in the world outside. I work as hard as I can to send you calm, don’t want my anxiety to mistransmit the message. You hear most of what I hear, just not Jóhannson’s Orphée in my ears as I write. Perhaps right now you hear movements in our home I’ve blocked out with my AirPods. You press your head down on my bladder, cephalic anterior. You invert with me when we do downward dog. You have no choice. I am your vehicle, Garuda to Vishnu, Nandi to Shiva, the mouse to Ganesha. Some people call the fetus a parasite. I feel more like I am a vehicle for your being and growth, my existence subordinated to give you life.
This state is temporary. Soon a new relationship will form as mother and child. You will still eat what I eat, through colostrum, then milk, not the fluid that surrounds you. You will still feel shadows of what I feel, no matter how hard I might try to control the states I transmit to you: your limbic system outsmarts your cortex, my cortex. You’ll hear more of what I hear. Sounds won’t be blocked behind the water womb. I’ll hear you for the first time. We’ll change how we communicate with one another. I will watch your eyes for cues, listen to grunts and swallows as you suck. I will watch how your fingers curl on your hands, your toes curl on your feet. You will watch my eyes, vague at first, but there. For now we communicate through touch alone. Because you are still me, I rub my stomach with the same pressure and circular movement I’ll use when I rub your infant back. I rub me as if I am rubbing you. I rub me to settle you down when you kick in frustration after the hiccups start. The hiccups come on slow, a pulse here and there in my belly that eventually settles into a regular cadence. And then you notice it, want it gone, increase the amplitude of your movements to try to get them to stop. We get up from bed together. We walk over to the room where I will nurse you after you’re born. I rub me to rub you, whisper that it will be ok, that they will go soon, that, like teething, this is a positive sign of growth. That growing up hurts. That this is the first of so many hurts and aches, nothing compared to the heartache of the first unrequited love, the rejection that feeds on unmatched desire. And you, too, communicate with me through touch. You punch the living day lights out of the membrane that surrounds your liquid world when I lie on my left side at night, telling me the only way you can that you hate what your vehicle is doing. I respond. Rotate. Settle onto the other side to grant you peace.
And it is not just growing up that hurts. Since you have been me, since those early days of cells dividing from one to two to four to eight to sixteen to all these powers of two cascading into being, days cloudy in my memory, far away now, sensations I have to stretch my memory to recall, how tired I felt walking up the hill that leads to our home, how tired I felt on walks near the Charles River in Boston or the Pacific Ocean in Victoria, when, pitched momentarily into old age, time somersaulted into the future. I had to sit down after a kilometer of movement to catch my breath. The miracle was that I welcomed the morning sickness (which lasted all day, and came more frequently at night) because it was a sign that you were alive. At that time there were no other signs. You didn’t kick yet. You didn’t squirm your fingers on my lower abdomen. I relied on my nausea to know you were safe. I welcomed the discomfort. When it subsided I worried, fretted that perhaps you weren’t viable. Waited anxiously for the sickness to return. It was all I had of you. And my relationship to the pain involved in bringing you to life changed. I suffered effortlessly because it meant you were ok. Abided in it. Practiced the patience I will need after you are born. And now as we prepare for labor I continue this practice. Your father and I invite situations of physical pain. We hold ice cubes in our hands and breathe through the sensation. We squeeze our toes under the weight of our bodies at yoga class and breathe through the sensations. He massages my perineal muscles, stretching muscles and skin that have never been stretched like this before. It burns. Screams with discomfort. And I breathe through it knowing that the work will help us with your birth. Again time somersaults. We are at once totally here, totally present, and present in the awareness of the work we are doing for that future moment. As I work to give you an unmedicated birth, work to feel you come through me into the world, where others can meet you (for I already know you, your father already knows you too, but not the same way I do), the most challenging exercise I face is that your birth may not be as I wish it to be. I may have to adapt, accept, follow medical protocol to ensure we are both safe, both alive through your phase shift, your coming to live in a new way. But for now, your father and I practice modifying my relationship to pain, and deepen our connection to one another through our work.
These visions, these hopes, can be empowering, dangerous, and absurd. Empowering because they can fuse mind and body to make birth beautiful by making birth mammalian. Marie Mongan opens her book on HypnoBirthing with an anecdote of watching a cat give birth to kittens. The cat first finds a dark, safe place, the kind of solitude we look for when having a bowel movement. And in this place of safety her body does its work, seemingly effortlessly although undoubtedly with pain. But upon sensing a threat, be that a dog or some other predator coming near, the birthing work halts. The cat closes up. Gets up. Walks away from the now endangered place and only returns when the signs of danger to her kittens has disappeared. This image resonates deeply. For I too am mammal, you too are mammal. We will need a place of safety to give my body the right cues to enable to uterus to push you into the world, to enable the cervix and pelvic floor muscles to stay relaxed rather than clenching and give you space, to focus the oxygen and blood on my abdomen rather than in my arms and legs so you have what you need to move down the birth canal. My mind can help, help by getting out of the way. Help by encountering the pain and sensations without fear, trusting them, trusting you who know much more about this than I. Dangerous because I cannot suffocate you, now or after you are born, with images of what I want you to become. You will be who you are, rife with eccentricities. You may not be like me. You may not be like your father. Sometimes I fear you will be deaf. I will still love you. As Alison Gopnik says, I will work to be your gardener, not your carpenter. I will create conditions for you to grow as you will, a being like me and unlike me. Will watch with surprise as you move in our space. I will not shape you in a pre-formed image, will not mold you and chisel you according to the formal cause (Aristotle) I’ve prefigured in my mind. No Silicon Valley Tiger Mom horror. I am sure it will pain me if for some reason your development is slower than others. I promise I will accept it with grace and do what I can to help you without loving you any less. As James Carse says, our relationship with one another will be an infinite game, not a finite game. I won’t block us from growing together in surprising ways because I feel I need to embody the role as mother. I will engage with you. Inhabit the world of your imagination, embrace it, welcome it as you teach me to recover poetry from prose. I will ask you why after you ask me why. Our conversation will never end, for at its heart will be the mysteries, the big things we never really understand. We’ll journey here together. Absurd because, as I’ve found in my last weeks working before I prepare for maternity leave, the reality of what the future brings is never what we planned. Situations arise. Challenges come upon us. I thought, at this point, I’d be coasting on the ideal of servant leadership, grappling with the recognition that I am not needed, preparing an organization for my impending departure with calm and grace and beauty. But the future wanted otherwise, as it seeps into my past. I am still working hard, solving hard problems, breathing day by day so my stress levels don’t impact you. Sometimes I feel like I’m in an Ionesco play laughing at what I thought this phase in my pregnancy would be like. In my best moments, I feel empowered. I think of you and how I want to be for you, and carry out my work with as much integrity as possible. I want to be strong for you. I want you to be able to watch your mother after you are born and smile, maybe not to your friends, but to yourself when no one is watching, because you have me as a role model. You have already given me strength. Already helped me become a better version of myself.
Your name is Felix. I wasn’t sure if I wanted to know your gender, but ultimately am grateful that we learned it because it deepened our connection to you, made you more concrete. At first you were just the baby, just it. When writing about you I’d either use they as a gender neutral pronoun or hop between he and she. And then you became he. And then you became you, Felix, not just the baby inside me, not just a baby, but this particular, unique, singular being. Granted as you grow into yourself outside my womb, your gender identity may evolve. That’s fine. Perhaps this is a temporary you.
Others will meet you in just a few weeks’ time. I won’t meet you then. I already know you. I don’t consider the moment of birth as one of your coming into the world. You are here, currently part of me, not visible to others the way they are used to being with others. Your birth is like a phase shift. Like plasma, you will take on a new form. Breathe in a new way. Eat in a new way. Your stomach will grow. You will poop black tar for the first time. You will take in the world in a new way. You will teach me as you take in the world. I will do my best to teach you, but I think I have more to learn from you than you from me. Someday you might read this and feel embarrassed. I get that. I’d feel that way too.
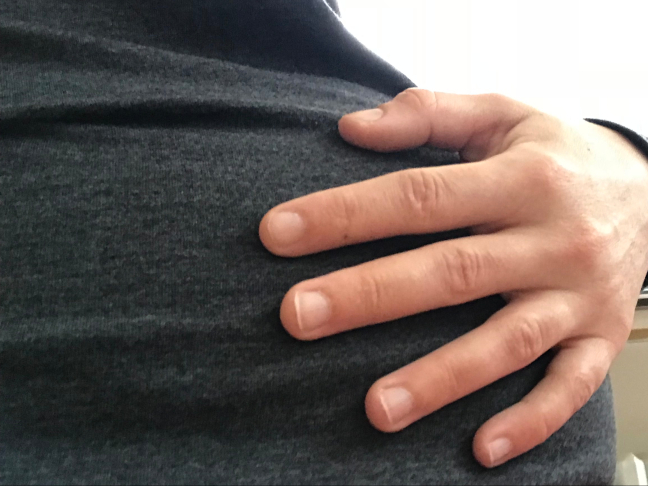
The featured imageis of my hand on my belly one week ago. I tried to write this post last week, but found I was revealing certain details I wasn’t comfortable sharing in this public forum. I stopped. I felt the pain of failure and wondered if I’d ever be able to write this post. Since then, I read Knaussgaard’s Spring, a novel where he addresses his 3-month-old daughter in the second person. It inspired me and give me the courage to write this post. The lyrical mode is protective, gives me the ability to reveal depth without disclosing too much of the particular.
“In the seventh century,” writes Lewis Mumford in Technics & Civilization, “by a bull of Pope Sabinianus, it was decreed that the bells of the monastery be rung seven times in the twenty-fours hours. These punctuation marks in the day were known as the canonical hours, and some means of keeping count of them and ensuring their regular repetition became necessary.” The instrument that would help the monasteries ring bells on a regular basis was the mechanical clock, whose “‘product’ is seconds and minutes.” Standard, measurable sequences of time not a latent property of the universe, but the output of a man-made machine. Mumford proposes that the monastic desire for order, the desire to cultivate a way of being where surprise, doubt, caprice and regularity were put at bay, was the cultural foundation that created the clock, but that the clock went on to “give human enterprise the regular collective beat and rhythm of the machine; for the clock is not merely a means of keeping track of hours, but of synchronizing the actions of men.”
This effect continues to impact us today. Most of us structure our existence by the synchrony of the industrial work week, waking up Monday through Friday at a certain time, commuting on crowded trains or highways with everyone else at a certain time, breaking for lunch at a certain time, showing up to meetings punctually and ordering the exchange of information and ideas to fit a pre-determined 30 or 60 minutes (the skill of managing meetings to maximize communicative efficacy a byproduct of the need to keep time), coveting weekends or vacations because we crave a moment of unstructured respite, crave the opportunity to vaunt our enlightened ability to take a device-free day (so we can return fresher and more productive on Monday), all-the-while watching Monday peer over the horizon and looking forward, once more, to the following Friday at 5:00 pm.
Perhaps more profoundly (or perhaps as a byproduct of the way we live day to day), we continue to share the assumption that time working normally is time that flows at the same, standard pace for all individuals and for the same individual at different periods in their life. I infer that this is a standard assumption because of how much it interests us to explore the contrary, namely that our subjective experience of time is not standard, that you might think our activity dragged on for hours while I thought it flashed by in seconds, that time from our childhood seemed to pass so much more slowly than it does in old age.
At 35, I cannot give a rich, inner account of what time feels like for a 70-year-old or 80-year-old. But over the past few weeks, I asked a handful of people 70 and above to describe their experience of time and account for why they think time feels faster as they get older. What follows are four accounts for why time speeds up as we age and a few suggestions for things we can do to slow time down. I take it for granted that slowing down time increases our sensation of living a meaningful life. For there is power in the continuum: if there’s an upper bound on the number of years we can live, why not focus on expanding our perception of the duration of each year, of each instant? At the theoretical limit, we would achieve immortality in a moment of living (an existentialist take on Zeno’s paradox, which any good pragmatist should and could easily shut down, and which Jorge Luis Borges elegantly explored in the Secret Miracle).
Why Does Time Speed Up as We Age?
Let’s start with a physics argument proposed by Duke professor Adrian Bejan. In his short article Why the Days Seem Shorter as We Get Older, Bejan focuses on how the structure of the eye changes with age, lengthening the periods between which we can perceive a change in a succession of images, i.e., can experience a unit of time:
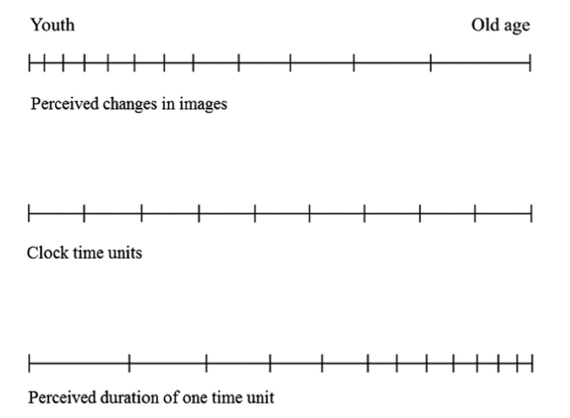
Time represents perceived changes in stimuli (observed facts), such as visual images. The human mind perceives reality (nature, physics) through images that occur as visual inputs reach the cortex. The mind senses ‘time change’ when the perceived image changes…The sensory inputs that travel into the human body to become mental images-‘reflections’ of reality in the human mind-are intermittent. They occur at certain time intervals (t1), and must travel the body length scale (L) with a certain speed (V)…L increases with age because the complexity of the flow path needed by one signal to reach one point on the cortex increases as the brain grows and the complexity of [path flows in the eye] increases…At the same time, V decreases because of the aging (degradation) of the flow paths. Two conclusions follow: (i) More recorded mental images should be from youth and (ii) The ‘speed’ of time perceived by the human mind should increase over life.
Graph from Bejan’s article, showing the inverse relation between the perceived changes in images and the perceived duration of a unit of time.
So, essentially, because we perceive fewer changes in images as we get older, time seems to flow more quickly.
Neuroscientist David Eagleman makes a similar argument with different rationale. Eagleman builds on experiments where people are shown images of cats, each image for 0.5 seconds. Experiment participants are presented with an image of the same cat multiple times, and then presented with an image of a different cat: results show that participants feel like the new cat is on the screen for a longer period of time (even though all images are presented for only 0.5 seconds). Eagleman’s conclusion is that “when the brain sees something that’s novel, it has to burn more energy to represent it, because it wasn’t expecting it. The feeling that things are going in slow motion is a trick of memory.” As children, he continues, we are constantly bombarded by novelty as we work to figure out the rules of the world and, importantly, write down a lot of memory. By contrast, in old age we sink into routines and habits, and no longer need to sample as much from the world to navigate it. Because we perceive less, we remember less, and looking back on the past year it seems to have flown by. Note the mechanisms accounting for time speeding up differ slightly from those provided by Bejan: Eagleman includes the mechanisms of expectation and memory, of our brain’s models of the world as the core explanation for why we seem to be taking in and recording less data from the environment we inhabit. Similar between the two, however, is that these mechanisms occur beyond the horizon of our own conscious perception-they happen without our knowing it or being able to describe the experience.
When I asked people in their 70s and 80s how time feels as they age, they all reported it seems to go by faster, but focused their explanations on higher-level relative experience.
Men tended to focus on the relative length of one day’s existence vis-a-vis the total amount of time they’d lived or the total amount of time they presumed they had left to live. So, if you’ve only lived 365 days, each day is 1/365th of your total existence; if you’ve lived 27,375 days (75 years old), each day is 1/27,375th of your total existence. As a much smaller percentage of your total lived experience it will feel like the day passes more quickly. The converse is the sense that there are fewer years left to live, as well as the increasing awareness of the inevitability and proximity of death. Here, each day feels more important, as there are only so many more to live. The subjective experience of time feels faster because it is more precious.
Women tended to focus on the perception of how quickly younger people (i.e., grandchildren) in their lives change. We grow and learn quickly as children (and sometimes as adults), but inhabiting our own consciousness, aren’t (often or always) observing ourselves in time-lapse. The changes occur quickly but nonetheless gradually and continuously, and absent epiphany we don’t factor our own change into our perception of time. But many grandparents, especially in North America, don’t see their grandchildren on a daily basis. They can observe massive week by week, or month by month, or year by year changes, which occur much faster than the sameness they perceive in their own minds, bodies, and existences. It was interesting to me that women focused more on their experience of others, that their very notion of time was relative to how they experience others. I don’t want to claim gender essentialism, and am sure there are men out there who would also focus their sense of time on changes they see in others. But this was what I found in my small interview sample.
How Can We Slow Down Time?
As mentioned above, I’m going to take for granted that we’d want to slow down time to live a richer and more meaningful life (rather than wanting time to speed up as we age to just get things over with). Here are a few ideas on things on to make that happen:
Introduce novelty into daily life - In the video above, Eagleman references activities as simple as brushing our teeth with the opposite hand or wearing our watch on the opposite hand. Various small actions we can take to break mundane habits that nonetheless force the brain to do more work than it normally does. An extreme example would be learning to ride a bike whose handles steer the wheel in the opposite direction we learned originally.
Travel - There’s a banal account of travel that would focus on seeing a new culture and exploring an environment different from the one we see every day. Another take on novelty. But I think the impact on travel can be much more profound. First, it’s an opportunity to consciously activate more of our senses than we pay attention to in our daily lives. I’m against the idea that viewing an image of a foreign place or experiencing it through virtual reality is enough to satisfy our craving to experience that new place. This betokens a focus on sight as the primary sense for knowledge, forgetting the importance of sound, smell, touch, and taste. When I visited Bangalore and Madurai, India, I was constantly amazed by the extreme juxtaposition of smells on the streets, where one second’s sensation of exhaust and filth would be followed by the second’s of jasmine whiffs from the woven necklaces at a small street stand. These smells oriented my sense of space, oriented what I saw around me and shaped my memories of the experience. Second, some of the most profound memories I have of time dilated almost to a standstill have been while traveling alone. Living outside any social connections and pressures, abstracted from my past as from my future to focus on the gait of passersby, of the tiredness I sense in my legs on day three after walking around cities or mountains to take in sights, on sensing aloneness without feeling the pangs of loneliness that one feels ensconced in a social context. Everything is heightened, even if I wish I had the opportunity to share what I’m experiencing with others. This isn’t just about novelty; it’s about providing a context to practice sensing more from the surrounding environment, without the myopia of driving an outcome or goal.
Do one thing at a time - This as living mindfully. Not just meditating 20 minutes per day, but doing daily activities in a mindful way. One of the hardest is to eat without doing anything else. I don’t mean focusing on the social bond created by sharing a meal with others. I mean eating by oneself without reading something or writing an email or watching TV or doing something else while eating. Just focusing on taste, texture, how long the food stays in the mouth before swallowing, what the plating looks like, what the colors look like, how it tastes to combine two things together (or whether it’s cleaner to keep them separate), what the temperature is like on tongue or lips or cheeks or glasses, what a utensil looks like as it interacts with food (like a spoon going in and out of soup), how the body’s sensations change during the meal. Eating is a good starting point that could serve as a practice ground for many other simple activities in life: walking, reading (without getting distracted by the internet), nursing a baby, caring for a sick person, sitting and breathing.
Enliven the present through analogy and memory - I recently read The Art of Living, which Buddhist monk Thich Nhat Hanh wrote at the age of 91. In one passage, Nhat Hanh shows how “ten minutes is a lot of a little [depending] on how we live them.” He goes on to describe how, when preparing for a talk, he “opened the faucet a little sot hat only a few drops came out, one by one.” He then imagined these icy drops as melted snow falling in his hand, which transported him back to memories of the Himalayan mountains he’d experienced in his youth, far away now that he was in a hut in a monastery in France. He then abided in the metaphor, seeing dew on the grasses he passed outside as he walked to his talk as more drops of Himalayan snow, seeing the water on his face and in his body as connected to this Himalayan snow. His account is interesting because it skirts how we normally think about mindfulness. This wasn’t about focusing attention to observe what’s there, but about hopping from one analogical connection to another to bring out unity in experience. Key, of course, was that he wasn’t focused on what came next, wasn’t anxious about what others would think about him when he gave his upcoming talk. He dilated a few drops of water into a grand theory of interconnectedness, traveling through the vehicle of his own associations and memories. As we age, we carry with us this lapsed time, these lapsed experiences. It may be that it’s how we relate to our own past that is the secret for how we expand the meaning of our present.
Conclusion
This post was primarily about sharing thoughts I’ve had over the past few weeks. The real significance is to try to recover the habit of writing regularly, a habit which has dwindled over the past year. One must start somewhere. I’ve always found that a regular writing practice expands what I perceive around me, as I feel motivated to capture as much as possible as material for what I’ll write. Perhaps that’s the dual significance of this post.
The featured image was taken at sunset in Grenadier Pond in High Park in Toronto in December, 2019. Mihnea and I were on an evening walk. The sun grew as it capped the horizon, pitching grass tufts into relief. A few people walked by with dogs; a woman insisted we walk further south to catch this beauty in a thick French accent. Time slowed as we focused on the changing hue of the grass tufts, which became darker at their center and lighter around the edges.
Most writing defending the value of the humanities in a world increasingly dominated by STEM focuses on what humanists (should) know. If Mark Zuckerberg had read Mill and De Tocqueville, suggests John Naughton, he would have foreseen political misuse of his social media platform. If machine learning scientists were familiar with human rights law, we wouldn’t be so mired in confusion on how to conceptualize the bias and privacy pitfalls that sully statistical models. If greedy CEOs had read Dickens, they would cultivate empathy, the skill we all need to “put ourselves in someone else’s shoes and see the world through the eyes of those who are different from us.”
I agree with Paul Musgrave that “arguments that the humanities will save STEM from itself are untenably thin.” Reading Aristotle’s Nicomachean Ethics won’t actually make anyone ethical. Reading literature may cultivate empathy, but not nearly enough to face complex workplace emotions and politics without struggle. And given how expensive a university education has become, it’s hard to make the case of art for art’s sake when only the extremely elite have the luxury not to build marketable skills.
But what if training in the humanities actually does build skills valuable for a STEM economy? What if we’ve been making the wrong arguments, working too hard to make the case for what humanists know and not hard enough to make the case for how humanists think and behave? Perhaps the questions could be: what habits of mind do students cultivate in the humanities classroom and are those habits of mind valuable in the workplace?
I wrote about the value of the humanities in the STEM economy in early 2017. Since that time, I’ve advanced in my career from being an “individual contributor” (my first role was as a marketing content specialist for a legal software company) to leading teams responsible for getting things done. As my responsibilities have grown, I’ve come to appreciate how valuable the ways of speaking, writing, reading, and relating to others I learned during my humanities PhD are to the workplace. As a mentor Geoffrey Moore once put it, it’s the verbs that transfer, not the nouns. I don’t apply my knowledge of Isaac Newton and Gottfried Leibniz at work. I do apply the various critical reading and epistemological skills I honed as a humanities student, which have helped me quickly grow into a leader who can weave the communication fabric required to enable teams to collaborate to do meaningful work.
This post describes a few of these practical skills, emphasizing how they were cultivated through deep work in the humanities and are therefore not easily replaced by analogue training in business administration or communication.
David Foster Wallace’s 2005 Kenyon College Commencement speech shows how powerful arguments in favor of a liberal arts education can be when they need not justify material payoff
Socratic Dialogue and Facilitating Team Discussion
Humanities courses are taught differently from math and science courses. Precisely because there is no one right answer, most humanities courses use the Socratic Method. The teacher poses questions to guide student dialogue around a specific topic, helping students question their assumptions and leave with a deeper understanding of a text than they did when they came to the seminar. It’s hard to do this well. Students get off topic or cite arguments or examples that aren’t common knowledge. Some hog the conversation and others are shy. Some teachers aren’t truly open to dialogue, and pretend the discuss when they’re really just leading students to accept their interpretation.
At Stanford, where I did my graduate degree, History professor Keith Baker stands out as the king of Socratic dialogue. Keith always reread required reading before class and opened discussion with one turgid question, dense with ways the discussion might unfold. Teaching D’Alembert and Diderot’s preface to the French Encyclopédie, for example, he started by asking us to explain the difference between an encyclopedia and a dictionary. The fact this feels like common sense is what made the question so poignant, and, for the French Enlightenment authors, the distinction between the two revealed much about the purpose of their massive work. The question forced us to step outside our contemporary assumptions and pay attention to what the same words meant in a different historical context. Whenever the discussion got off track, Keith gracefully posed a new question to bring things back on point without offending a student, fostering a space for intellectual safety while maintaining rigor.
The habits of mind and dialogue trained in a Socratic seminar are directly applicable to product management, which largely consists in facilitating structured discussions between team members who see a problem differently. In my work leading machine learning product teams, I frequently facilitate discussions with scientists, software developers, and business subject matter experts. Each thinks differently about what should be done and how long it will take. Researchers are driven by novelty and discovery, by developing an algorithm that pushes the boundary of what has been possible but which may not work given constraints from data and the randomness in statistical distributions. Engineers want to find the right solution to meet the constraints for a problem. They need clarity and don’t mind if things change, but need some stability so they can build. The business team represents the customer, focusing on success metrics and what will please or hook a user. The product manager sits between all these inputs and desires, and must take into account all the different points of view, making sure everyone is heard and respected, but getting the team to align on the next action.
Socratic methods are useful in this situation. People don’t want to be told what to do; they want to be part of a collective decision process where, as a team, they have each put forth and understood compromises and trade-offs, and collectively decided to go forward with a particular approach. A great product manager starts a discussion the same way Keith Baker would, by providing a structure to guide thinking and posing the critical question to help a group make a decision. The product manager pays attention to what everyone says, watches body language and emotional cues to capture team dynamics. She nudges the dialogue back on track when teams digress without alienating anyone and builds a moral of collective and autonomous decision making so the team and progress forward. She applies the habits of mind and dialogue practiced in the years in a humanities classroom.
Philology and Writing Emails for Many Audiences
My first year in graduate school, I took a course called Epic and Empire, which traced the development of the Western European epic literary tradition from Homer’s Iliad to Milton’s Paradise Lost. The first thing we analyzed when starting a new text was how the opening lines compared and contrasted to those we’d read before. Indeed, epics start with a trope called the invocation of the muse, where the poet, like a journalist writing a lede, informs the reader what the subject of the poem is about using a humble-boasting move that asks the gods to imbue him with knowledge and inspiration.
So Homer in the Iliad:
Sing, Goddess, sing the rage of Achilles, son of Peleus— that murderous anger which condemned Achaeans
And Vergil signaling that the Aeneid is Rome’s answer to the Iliad, but that an author as talented as Vergil need not depend on the support from the gods:
Arms and the man I sing, who first made way, predestined exile, from the Trojan shore to Italy, the blest Lavinian strand.
And Ariosto, an Italian author, coyly signaling that it’s time women had their chance at being the heroines of epics (the Italian starts with Le Donne):
Of loves and ladies, knights and arms, I sing,
Of courtesies, and many a daring feat;
In the same strain of Roland will I tell
Things unattempted yet in prose or rhyme…
And finally Milton, who, at the time when Cromwell was challenging the English monarchy, signals his aim to critique contemporary politics and society by daftly merging the Judaic and Greek literary traditions:
OF Mans First Disobedience, and the Fruit
Of that Forbidden Tree, whose mortal tast
Brought Death into the World, and all our woe,
With loss of Eden, till one greater Man
Restore us, and regain the blissful Seat,
Sing Heav’nly Muse…
Studying literature this way, one learns not just knowledge of historical texts, but the techniques authors use to respond to others who came before them. Students learn how to tease out an extra layer of meaning above and beyond what’s written. The first layer of meaning in the first lines of Paradise Lost is simply what the words refer to: this is a story about Adam and Eve eating the forbidden fruit. But the philologist sees much more: Milton decides to hold the direct invocation to the muse until line six so he could foreground a succinct encapsulation of the being in time of all Christians, waiting from the time of the fall until the coming of Christ; does that mean he wanted to signal that first and foremost this is a Christian story, with the Greek tradition, signaled by the reference to Homer, only arriving 5 lines later?
Reading between the lines like this is valuable for executive communications, in particular in the age of email where something written for one audience is so easily forwarded to others without our intending or knowing. Business communications don’t just articulate propositions about states of affairs; they present facts and findings to persuade someone to do something (to commit resources to a project, to spend money on something, to hire or fire someone, to alter the way the work, or simply to recognize that everything is on track and no worry is required at this time). Every communication requires sensitivity to the reader’s presumed state of mind and knowledge, reconstructing what we think they know or could know to ensure the framing of the new communication lands. Each communication should build on the last communication, not using the stylistic invocation to the muse like Homer, but presenting what’s said next as a step in a narrative in time. And at one moment in time, different people in different roles interpret communications differently, based on their particular point of view, but more importantly their particular sensitivities, ambitions, and potential to be threatened or impacted by something you say. Executives have to think about this in advance, write things as if they were to be shared far beyond the intended recipient with his or her point of view and stakes in a situation. Philology training in classes like Epic and Empire is a good proxy for the multi-vocal aspects of written communications.
Making Sense of Another’s World: The Practice of Analytical Empathy
In 2013, I gave a talk about why my graduate work in intellectual history formed skills I would later need to become a great product marketer. As in this post, my argument in that talk focused not on what I knew about the past, but how I thought about the past: as an intellectual historian focused on René Descartes’ impact on 17th-century French culture, I sought to reconstruct what Descartes thought he was thinking, not whether Descartes’ arguments were right or wrong and should continue to be relevant today or relegated to the dustbin of history (as a philosopher would approach Descartes).
Doing this well entails that one get outside the inheritance of 400 years of interpretation that shape how we interpret something like Descartes’ famous Cogito, ergo sum, I think, therefore I am. Most philosophers get accustomed to seeing Descartes show up as a strawman for all sorts of arguments, and consider his substance dualism (i.e., that mind and body are totally separate kinds of matter) is junk in the wake of improved understanding about the still mysterious emergence of mind from matter. They solidify an impression of what they think he’s saying as seen from the perspective of the work philosophy and cognitive science seeks to do today. As an intellectual historian, I sought to suspend all temptation to read contemporary assumptions into Descartes, and to do what I could to reconstruct what he was thinking when he wrote the famous Cogito. I read about his upbringing as a Jesuit and read Ignatius of Loyola’s Spiritual Exercisesto better understand the genre of early-modern meditations, I read the texts by Aristotle he was responding to, I read seminal math texts from the Greeks through the 16th-century Italians to understand the state of mathematics at the time he wrote the Géometrie, I read not only his Meditations, but also all the surrounding responses and correspondence to better understand the work he was trying to accomplish in his short and theatrical philosophical prose. And after doing all this work, I concluded that we’ve misunderstood Descartes, and that is famous Cogito isn’t a proposition about the prominence of mind over body, but rather a meditative mantra philosophers should use to train their minds to think “clear and distinct” thoughts, the axiomatic backbones for the method he wanted to propose to ground the new science. And Descartes was aware we are all to prey to fall into old habits, that we had to practice mantras every day to train the mind to take on new habits to complete a program of self-transformation. I didn’t care if he was right or wrong; I cared to persuade readers of my dissertation that this was the work Descartes thought the Cogito was doing.
A talk I gave in 2012 about why my training in intellectual history helped be become a good product marketer, a role that requires analytical empathy.
This skill, the skill of suspending one’s own assumptions about what others think, of not approaching another’s worldview to evaluate whether its right or wrong, but of working to make sense of how another lives and feels in the world, is critical for product management, product marketing, and sales. Product has migrated from being an analytical discipline focused on triaging what feature to build next to maximize market share to being an ethnographic discipline focused on what Christian Madsbjerg calls analytical empathy (Sensemaking), a “process of understanding supported by theory, frameworks, and an engagement with the humanities.” This kind of empathy isn’t just noticing that something might be off with another person and searching to feel what that other person likely feels. It’s the hard work of coming to see the world the way another sees it, patiently mapping the workflows and functional significance and emotions and daily habits of a person who encounters a product or service. When trying to decide what feature to build next in a software product, an excellent product manager doesn’t structure interviews with users by posing questions about the utility of different features. They focus on what the users do, seek to become them, just for one day, watch what they touch, what where they move cursors on screens, watch how the muscles around their eyes tighten when they get frustrated with a button that’s not working or when they receive a stern email from a superior. They work to suspend their assumptions about what they assume the user wants or needs and to be open to experiencing a whole different point of view. Similarly, an excellent sales person comes to know what makes their buyers tick, what personal ambitions they have above and beyond their professional duties. They build business cases that reconstruct the buyers’ world and convincingly show how that world would differ after the introduction of the sellers’ product or service. They don’t showcase bells and whistles; they explain the functional significance of bells and whistles within the world of the buyer. They make it make sense through analytical empathy.
Business school, in particular as curriculum exists today, isn’t the place to practice analytical empathy. And humanities courses that are diluted to hone supposedly transferrable skills aren’t either. The humanities, practiced with rigor and fueled by the native curiosity of a student seeking deeply to understand an author they care about, is an avenue to build the hermeneutic skills that make product organizations thrive.
Narrative Detail Helping with Feedback and Coaching
It’s table stakes that narrative helps get early funding and sales at a startup, in particular for founders who lack product specificity and have nothing to sell but an idea (and their charisma, network, and reputation). But the constraints of the pitch deck genre are so formulaic that humanities training may be a crutch, not an asset, to succeeding at creating them. Indeed, anyone versed in narratology (the study of narrative structure) can easily see how rigid the pick deck genre is, and anyone with creative impulses will struggle to play by the rules.
I first understood this while attending a TechStars FinTech startup showcase in 2016. A group of founders came on stage one by one and gave pithy pitches to showcase what they were working on. By pitch three, it was clear that every founder was coached to use the exact same narrative recipe: describe the problem the company will address; imagine a future state changed with the product; sketch the business model and scope out the total addressable market; marshal biographical details to prove why the business has the right team; differentiate from competitors; close with an ask to prospective investors. By pitch nine, I had trouble concentrating on the content beyond the form. It reminded me of Vladimir Propp’s Morphology of the Folktale.
20th-century Russian literary theorist Vladimir Propp analyzed the formal structure common to folktales. My sensitivity to literary form makes me cynical about the structure of startup pitch decks and yearning for something creative and new.
This doesn’t mean that storytelling isn’t part of technology startup lore. It is. But the expectations of how those stories are told is often so constrained that rigorous humanities training isn’t that helpful (and it’s downright soul-destroying to feel forced to adopt the senseless jargon of most tech marketing). In my experience, narrative has been more poignant and powerful in a different area of my organizational life: coaching fellow employees through difficult interpersonal situations or life decisions.
A first example is the act of giving feedback to a colleague. There are many different takes on the art of making feedback constructive and impactful, but the style that resonates most with me is to still all impulses towards abstraction (“Sally is such a control freak!”) and focus on the details of a particular action in a particular moment (“In yesterday’s standup, Sally interrupted Joe when he was overviewing his daily priority to say he should do his task differently than planned.”). As I described in a former post, what sticks with me most from my freshman year Art History 101 seminar was learning how to overcome the impulse towards interpretation and focus on observing plain details. When viewing a Rembrandt painting, everyone defaulted to symbolic interpretation. And it took work to train our vision and language to articulate that we saw white ruffled shirts and different levels of frizziness in curly hair and tatters on the edges of red tablecloths and light emanating on from one side of the painting. It’s this level of detailed perception that is required to provide constructive feedback, feedback specific enough to enable someone to isolate a behavior, recognize it if it comes up again, and intentionally change it. When stripped of the overtones of judgment (“control freak!”) and isolated on the impact behavior has had on others (“after you said that, Joe was withdrawn throughout the rest of the meeting”), feedback is a gift. Now, no training in art history or literature prepares one to brace the emotional awkwardness of providing negative feedback to a colleague. I think that only comes through practice. But the mindset of getting underneath abstraction to focus on the details is certainly a habit of mind cultivated in humanities courses.
A second example is in relating something from one’s own experience to help another better understand their own situation. Not a day goes by where a colleagues doesn’t feel frustrated they have to do task they feel is beneath them, anxious about the disarray of a situation they’ve inherited, confused about whether to stay in a role or take a new job offer, resentful towards a colleague for something they’ve said or done, etc… When someone reaches out to me for advice, I still impulses to tell them what to do and instead scan my past for a meaningful analogue, either in my own experience or someone else’s, and tell a story. And here narrative helps. Not to craft a fiction that manipulates the other to reach the outcome I want him or her to reach, but to provide the right framing and the right amount of detail to make the story resonate, to provide the other with something they can turn back to as they reflect. Wisdom that transcends the moment but can only be transmitted in full through anecdote rather than aphorism.
Leadership Communication
I’ll close with an example of an executive speech act that humanities education does not help prepare for. A constructive and motivating company-wide speech is, at least in my experience, the hardest task executives face. Giving an excellent public speech to 2000 people is a cakewalk in contrast to giving a great speech about a company matter to 100 colleagues. The difficulty lies in the kind of work a company speech does.
The work of a public speech is to teach something to an audience. A speaker wants to be relevant, wants to know what their audiences knows and doesn’t know, reads and doesn’t read, to adapt content to their expectations and degree of understanding. Wants to vary the pace and pitch in the same way an orchestra would vary dynamics and phrasing in a performance. Wants to control movement and syncopate images and short phrases on a slide with the spoken word to maximally capture the audiences’ attention. There are a lot of similarities between giving a great university lecture and giving a great talk. This doesn’t mean training in the humanities prepares one for public speaking. On the contrary, most humanists read something they’ve written in advance, forcing the listener to follow long, convoluted sentences. Training in the humanities would be much more beneficial for future industry professionals if the format of conference talks were a little more, well, human.
The work of a company speech is to share a decision or a plan that impacts the daily lives and sense of identity of individuals that share the trait that, at this time, they work in a particular organization. It’s not about teaching; the goal is not to get them to leave knowing something they didn’t know before. The goal is to help them clearly understand how what is said impacts what they do, how they work, how they relate to this collective they are currently part of, and, hopefully, to help them feel inspired by what they are asked to accomplish. Unnecessary tangents confuse rather than delight, as the audience expects every detail to be relevant and cogent. Humor helps, but it must be tactfully displayed. It helps to speak with awareness of different individuals’ predispositions and fears: “If I say this this way, Sally will be reminded of our recent conversation about her product, but if I say it that way, Joe will freak out because of his particular concern.” People join and leave companies all the time, and a leader has to still impulses towards originality to make sure newcomers hear what others have heard many times before without boring people who’ve been in the company for a while. The speech that resonates best is often extremely descriptive and leaves no room for assumption or ambiguity: one has to explicitly communicate assumptions or rationale that would feel cumbersome in most other settings, almost the way parents describe every next movement or intention to young children. At the essence of a successful company talk is awareness of what everyone else could be thinking, about the company, about themselves, and about the speaker, as one speaks. It’s a funhouse of epistemological networks, of judgment reflected in furrowed brows and groups silently leaving for coffee to complain about decisions just after they’ve been shared. It’s really hard, and I’m not sure how to train for it outside of learning through mistakes.
What This Means for Humanities Training
This post presented a few examples of how habits of mind I developed in the humanities classroom helped me in common tasks in industry. The purpose of the post is to reframe arguments defending the value of the humanities from knowledge humanists gain to the ways of being humanists practice. Without presenting detailed statistics to make the case, I’ll close by mentioning Christian Madsbjerg’s claim in Sensemaking that humanities students may be best positioned for non-linear growth in business careers. They start off making significantly lower salaries than STEM counterparts, but disproportionately go on to make much higher salaries and occupy more significant leadership positions in organizations in the long run. I believe this stems from the habits of mind and behavior cultivated in a rigorous humanities education, and that we shouldn’t dilute it by making it more applicable to business topics and genres, but focus on articulating just how valuable these skills can be.
The featured image is of the statue of David Hume in Edinburgh. His toe is shiny because of tourist lore that touching it provides good fortune and wisdom, a superstition Hume himself would have likely abhorred. I used this image as the nice low-angle shot made it feel like a foreboding allegory for the value of the humanities.
This is the fourth post in an indefinite series on love. Here are post 1, post 2, and post 3. Someday the love series will coalesce into a book.
A master in the dark arts of anxiety with a mystic’s appreciation for the beauty latent in our day-to-day, I’ve listened to countless podcasts about meditation. My favorites, like this Tim Ferriss podcast with Jack Kornfield or this Krista Tippett podcast with Carlo Rovelli, brought tears to my eyes as I listened to them walking to work.[1] I’d take a moment to recompose before entering the office, hang up my coat, and walk-more like jog-directly to Charu Jaiswal and Katharine Marek, two former colleagues, gushing with enthusiasm about what I’d heard and watching them react with combination of surprise at being accosted, curiosity about the content, and joy at the purity of my intent.[2] Through all these hours of listening, however, I never heard anyone speaking about meditating with another.[3] I don’t mean next to someone, but entangled with someone, touching him or her, looking into his or her eyes, meditating together to feel, think, and breath as one. Love as meditation, or meditation as love.
I bet it would strike most as horrendously awkward and invasive to meditate looking directly into another’s eyes, even if they were the eyes of a lover or spouse. Context alters what feels natural: gazing into someone’s eyes is romantic on a first date, bonding after sex (when authentic…), and cherished during a proposal. But pausing our lives to sit down and look at one another without speaking just feels weird. It’s certainly not something we’d practice at a yoga class or meditation retreat. Sitting for five minutes in silence with strangers at a respectable distance is hard enough; having strangers sit on top of us and look into our eyes would annihilate any sliver of the inner peace and focus meditation is designed to promote.
But it’s deeper than that. The way of being we cultivate during meditation is a often a being disentangled from the minds and emotions of others. The quest in the west is to use meditation to appease our anxiety, depression, and fear, to chip away at crusty carapaces of self-hatred we’ve built over the years. It’s a hermetic place guarded in ritual, a precious state of mind that is relief from the turbulence and distraction we return to the minute we turn off our app and check email or Facebook. Many meditators find it difficult to bring the inner stillness they find on the mat to the office chair or the grocery store check-out line. The world impinges on us. Others impinge on us, entangling their histories, their emotions, their states with ours. And the spell is broken.
This isn’t to say that this is what meditation should and could be about. On the contrary, practices like metta (loving kindness) are geared towards focusing on others, wishing well-being, safety, and health to loved ones and strangers alike. The enlightened are beyond the petty, world-forming powers of anxiety, envy, and ambition, able to embrace all with equanimity and love divorced from the pain of projected possibility and power. In Buddhism, as far as I understand it, each person’s meditation promotes all beings’ ability to liberate ourselves from samsara, the purgatorial repetition of earthly existence characterized by suffering. So there should and could be value in practicing being fully connected with another, finding the same inner silence we encounter sitting by ourselves while our minds and emotions are entangled with another’s. Making space for emotions and thoughts we can’t control or directly observe and all the while experiencing deliverance.
My fiancé Mihnea and I recently started an almost daily practice of meditating with one another. On one another. In one another. We didn’t start on a quest for entangled enlightenment. We started because I wanted to meditate and we wanted to be together and it didn’t feel right to meditate next to one another, apart and independent, because we don’t love that way. It’s not our way of being. Ours is a love of oneness and interdependence, so it was more natural for us to meditate on one another than next to one another. So began a practice that yielded challenging and graceful experiences neither of us expected.
Here’s a sample. Mihnea has told me that he recognizes his own experiences in these descriptions.
How We Sit
Both Mihnea and I are prolific creators. We create to find stillness. We write, learn, build teams, build futures, ground our constant creativity in disciplined habits and rituals. As creators, we both have the instinct to experiment with meditation techniques and poses, to make meditation itself an instance of creative power. And yet, we (almost) always meditate in the same position: he sits on a couch or chair and I straddle him with my knees bent. Our perspectives are different: I tilt my head down and he tilts his up, when he bends his neck I see the crown of his head and when I bend mine he sees the tip of my forehead, I look down into his eyes and he looks up into mine.
My hunch is that we keep returning to this same position because it foregrounds the ability to look directly into one another’s eyes (or perhaps not, perhaps it’s all awaiting and preparation, twenty minutes spent building magnetic potential like rising bread that finds release in an embrace that is deep, pure, reaching towards essence, in the moment when I collapse into his chest like a child and he softens his hands to stroke my back and kiss my hair, a moment bursting with waiting, watching, noticing what wonders emerge when the world stretches flat from the density of a concentrated gaze). During a recent sit, Mihnea’s gaze hit me like a solid beam, unearthing a latent memory of the early Italian Renaissance Neoplatonic philosopher Marsilio Ficino, who described the eyes as a conduit to exchange blood and spirits, capable of beaming soul-rays into another. Here’s his commentary on Plato’s Phaedrus in De Amore [4]:
Put before your eyes, I beg of you, Phaedrus the Myrrhinusian, and that Theban who was seized by love of him, Lysias the orator. Lysias gapes at the face of Phaedrus. Phaedrus aims into the eyes of Lysias sparks of his own eyes, and along with those sparks transmits also a spirit. The ray of Phaedrus is easily joined to the ray of Lysias, and spirit easily joined to spirit. This vapor produced by the heart of Phaedrus immediately seeks the heart of Lysias, through the hardness of which it is condensed and turns back into the blood of Phaedrus as before, so that now the blood of Phaedrus, amazing though it seems, is in the heart of Lysias. Hence each immediately breaks out into shouting: Lysias to Phaedrus: “O, my heart, Phaedrus, dearest viscera.” Phaedrus to Lysias: “O, my spirit, my blood, Lysias.”
The lower-left corner detail of Domenico Ghirlandaio’s Zachariah in the Temple (this fresco has as many names as there are websites), in the church of Santa Maria Novella in Florence. Marsilio Ficino is the guy on the far left. My friend Andrew Hui, who teaches at Yale’s NUS college in Singapore, has written extensively about palimpsest temporality in the Renaissance, where recognizable contemporaries in modern clothing stand alongside spiritual figures from the Bible, as if the stories were happening in today. The temporality of allegory is non-linear: it’s ever present and wraps around itself in quantum loops, like Mihnea’s gentle hand bringing me back to my childhood. This fresco is a great example, with Ficino and his cohort present in a Jewish-temple-turned-Catholic-Church to watch the archangel Gabriel announce a child to Zachariah first hand.
Humoring Renaissance Humorism and Christian-mystic-transubstantation, there is something intense and powerful about our eyes becoming vessels to exchange blood and bile. While we meditate, it’s clear that our connection is centered through our eyes. The many other channels of communication and connection-my hands on his stomach breathing his breath, my bottom sensing pulses and twitches in his quadriceps, the heat from his body creating a temperature differential between my chest (facing him) and back (facing away)-are present but dim in contrast to the encompassing power of Mihnea’s gaze, the window to the inside, the locus that dominates my awareness and makes the rest feel like static in the background, surprising me when it comes to the fore. Given this connection, we often meditate with our eyes open; indeed, it feels slightly awkward for me when I close my eyes, as if I’m cutting off our connection and imparting distance. I’m learning to see with my eyes closed, to be ok if his eyes remain open and watching even when my eyes are closed. To feel blood seep through eyelid gates and pump his heart with mine.
My knees inevitably get so sore I have to lie flat and stretch them after we sit. Once we inverted our positions and he sat on me; he wasn’t heavy but fear that he would be tightened his leg muscles. I tried to relax him. Someday I’d like us to stand holding hands, stand with our hands down near our haunches but with some part touching one another, lie on our sides facing one another, lie as if we were two dead people in coffins with my back touching his front, sit with our backs facing one another, etc. There’s no rush.
Breathing in Syncopation
One of the first things a new meditator learns is how to focus on the breath. Breathing is a marvelous anchor because we all easily recognize it as an eminently noticeable act that almost always goes unnoticed as we think about or do something else. The psychologist William James went so far as to claim that consciousness is nothing but breath, and that what we mistake for consciousness is a fictitious thing philosophers made up to name the thing that knows its thinking:
I am as confident as I am of anything that, in myself, the stream of thinking (which I recognize emphatically as a phenomenon) is only a careless name for what, when scrutinized, reveals itself to consist chiefly of the stream of my breathing. The ‘I think’ which Kant said must be able to accompany all my objects, is the ‘I breath’ which actually does accompany them. There are other internal facts besides breathing (intracephalic muscular adjustments, etc., of which I have said a word in my larger Psychology), and these increase the assets of ‘consciousness,’ so far as the latter is subject to immediate perception; but breath, which was ever the original of ‘spirit,’ breath moving outwards, between the glottis and the nostrils, is, I am persuaded, the essence out of which philosophers have constructed the entity known to them as consciousness. That entity is fictitious, while thoughts in the concrete are fully real. But thoughts in the concrete are made of the same stuff as things are. (Italics original)
There are different breathing techniques and different techniques for attending to breath. I like to start a meditation session with controlled, hyper-dilated breathing: 60-second inhale-exhale cycles dabbled with rapid cycles if I get short of breath. Five breaths (minutes) in, I notice that my brain feels different. It’s hard to describe, but it’s as if the center of my brain’s activity shifts from the forehead to the back of the skull, as if a spidermonculus had emerged from hibernation in my axons to canvas my neural pathways in delicate, shimmying webs. Eventually I stop controlling the pace and observe myself breathing naturally. While keeping partial attention on the breath, I sometimes expand awareness to scan the sensations in one localized body part, like my right pinky toe; this lopsided focus is most fun when it induces pinky toe hallucinations, stretching my torso and face into oblong pizza dough like a reflection in a funhouse mirror. Dogmatic mindfulness meditators insist that one shouldn’t control the breath actively, that the practice is about noticing what the mind and body are doing and stilling the instinct to control. The breath, in mindfulness, is a home base to return to when thoughts do what thoughts do and plan and worry and wonder and plan and worry and wonder and criticize and compare and plan and worry and criticize and evaluate and self-hate and worry about planning and remember and ruminate and plan about worrying and ruminate about self-hate and remember about planning and plan about worrying ad infinitum. In the pranayama tradition, mediators actively restrict the breath using fingers or hold the breath at the top or bottom of a cycle.[5] Given my proclivities for experimentation, I like to experiment with different techniques and observe what happens.
When Mihnea and I started meditating together, I began with my habitual practice of long, controlled inhales and exhales. But it didn’t work. My prefrontal cortex stayed engaged, comparing my breathing cycle with his. I observed myself as I imagined he observed me, projecting my meditative I into his gaze such that the I watching me breathe was no longer the meditative I, but a socialized I, an outside I seeing my face and skin, judging me within my projections of what another sees. This doesn’t mean this is what Mihnea sees, or even what I think Mihnea sees. It was rather that his presence activated my superego, activated a bifurcation of the observing I that includes the awareness that others are watching. The discomfort was exacerbated by frustration: I sought to replicate the experience I cherish when meditating alone and felt budding frustration that I wasn’t able to replicate it, that the situation was different, that I didn’t have the same control.
So I pivoted. Focused on his breath instead of mine. It’s a different experience, a different way to cultivate inner stillness, but a way better suited to meditation with another. When I focus on my own breath, the act of attention is coupled with an act of will that controls the observed phenomenon: as I observe myself breathing at a pace I dictate, it’s as if my body were an extension of my attention. When I focus on his breath, the act of attention is decoupled from the observed phenomenon: sometimes Mihnea will imitate my breathing pace, but it normally lasts no more than 2-3 cycles. I notice the union and the difference, but the syncopation doesn’t bug me or create distance between us. It brings me closer to him, attunes me to him to the point where I stop noticing me and identify entirely with his breathing instead. It’s even deeper when I place my hands on his front body, palms facing down, one hand on his chest and one hand on his abdomen. My hands become like eyes, absorbing the heat and movements from his body as if they were x-rays observing his inner motions. When my hands breathe his breath, I close my eyes to amplify the sensation. It’s one of the few times when I feel more comfortable meditating with him with my eyes closed.
When I close my eyes and breathe Mihnea’s breath in my hands, it’s as if my hands were able to see him, the way an octopus can see through its arms. A firm believer in decentralization, I often dream of creating a company with an octopus leadership structure: I’d like to be a puny octopus brain CEO, delegating whole nervous systems to my teams, each of which can cognize the world independently yet somehow avoid the perils of silo’d, product-centric fragmentation. I also think the nervous structure of an octopus is a wonderful inspiration for distributed computational architecture, which seems to be where we’re headed.[6]
Mihnea recently built an application that synchronizes breathing in a group of people. Users put a belt around their chest to measure and join breath cadences. His research has shown that people who breathe in sync are more likely to register and remember the same thing: they become like one observer. I’ve certainly experienced communion like this in group meditation sessions, the experience strongest when the sound of my Om harmonizes with the resounding Oms of others (best when there are baritones and basses present). I think this makes the syncopation between Mihnea and my breath in our private meditation all the more interesting. We don’t breath in sync. But it’s precisely the syncopation that draws me out of myself and onto him, to decouple attention from will and give myself to his being.
Adding the octopus image reminded me of my favorite sea creature, the leafy sea dragon. You can view these in the Academy of Sciences in San Francisco’s Golden Gate Park.
Knowing the Self Through Touch
Whereas I place my hands on Mihnea’s chest and torso to breathe his breath, he laces his fingers behind the small of my back to balance and support me. The awareness of me in his hands, of his hands on me, interestingly, is an outside-in way of perceiving the self, a meditation practice emphasizing self and mind as integrated with body (Yoga is similar, just aligning mind with body through movement rather than focusing on the self as body through touch). Note that the organic awareness of the boundaries of the self through touch is very different from the deleterious projections of how another would see the self as described above. Watching hands don’t judge, the feel their way to vision.
Finding self awareness in touch (rather than through a recursive loop in the mind) reminds me of responses some French Enlightenment philosophers had to Cartesian epistemology. Descartes emphasized the split between the res cogitans (thinking thing) and the res extensa (extended thing, or matter), claiming that we can build the world (and God) from a clear and distinct perception of the self because it’s impossible to say “I don’t exist” (who’s the I who says I don’t exist?).[7] A corollary was that knowledge does not depend on sensory experience, that truth is pre-wired in the mind (explanation beyond the scope of this post). Enlightenment empiricists thought this was bollocks and worked to show how all knowledge starts with sensory experience. One of my favorite pieces in the tradition (referenced in a former post on consciousness), is Etienne Bonnot de Condillac‘s Treatise on Sensations, which opens with a fable about a statue that comes to know herself by touching another, implying that the mind alone does not suffice to stratify the self. Here’s how I paraphrased Condillac on May 21, 2010:
Imagine a statue that can only smell. Waft a rose under its nose. To an observer, it will be a statue that smells a rose. But to itself, it will simply be the oder of rose, of carnation, of jasmine, of violet, according to the objects that stimulate it. The odors the statue smells will seem to it not as properties of an external object, but rather as its own manners of being. Now think that the statue can only hear. Again, when the wind blows the oak leaves and rustles the willows, it will be that rustle and when the rain pitters the roof above, it will pitter with the rain. Now let the statue only be able to taste and smell. Place on its tongue your honey and thyme, and it will be that honey and thyme. Place on its tongue your cream and your salt, and it will be your cream and salt. It will be a collection of manners of being.
Now let the statue touch. First let the statue touch its own hands, its own legs. Then, place a rock on the table in front of your statue and let it touch it. It will rapidly pull back its hand in fear! For the statue will know that its me, the me that feels modified in its hands, does not feel modified in its body when it touches the rock. It is, then, the sensation of touch by which the soul passes from itself outside itself. By touching the rock, your statue will awake to its existence as different from the rest of the external world.
Now, Pygmalion, let the statue touch your own hand. Wait out your statue’s initial fear. Gradually, she will recognize that you are like her, a form similar to her own. But she will recognize that you are more than her and will think that her existence might change places and pass entirely into this second half of herself. She will want to give you all her being; a vivid desire will return and take over her whole existence, as a new manner of being, as a new awareness of a self that is a complete surrender of self into another. She will feel the birth of a sixth sense. Let us call this sixth sense dependence, vulnerability, or love.
Mihnea’s hands, however, do more than anchor me in the present as a body in space. They open another dimension and transport me through time. He has stubby fingers, incommensurate with the grace of his being. But he’s an extremely skilled pianist who expresses the musicality of his being-and the musicality of the world channeled through his being-through touch, absorbing and reflecting my needs and emotionality. When he strokes my hair, he transports me back to my childhood: I am three again, five again, comforted at last by my parents’ touch after hours of fretful insomnia. His hands cradle my fear and remind me I am no longer alone, ease me to sleep after the storm. Time unfolds in our moment of meditation, collapsing my life into the sensation of his fingers on my back. It pulses, breathing like a seal asleep under beach sun.
Practicing Stillness When Entangled With Another’s Mind
A Mind Like Sky is one of my favorite Jack Kornfield meditations. It calls for expansive attention (rather than the focused and controlled attention described above) to cultivate a mind “vast like space, where experiences both pleasant and unpleasant can appear and disappear without conflict, struggle or harm.” (From the Majjhima Nikaya) Every once and a while when I practice like this, the boundaries between myself and other relax (it’s too strong to say disappear). I identify with the sky, with the vase of breadsticks sitting askant to my left as I write, with the red spindly branches of the still leafless plant on our back porch. When the boundaries of the self expand to include and encompass everything, our ethical calculus changes. The golden rule stops making sense.
I have yet to feel this kind of universal identification when meditating with Mihnea. I trust it will come in time, but so far having my mind entangled with his has thwarted my ability to generalize my self awareness: his powerful and immediate presence grounds me in an us that is part of but not inclusive of everything. This is in part caused by the inviscid movements of our non-verbal communication. When Mihnea notices something that stimulates him, his eyes flicker and twitch with activity. When his eyes spark during meditation, I wonder what he’s thinking, what he noticed, get locked in his mind’s movement. Sometimes he opens his eyes so wide that the skin on his forehead folds like waves on a pond. His mouth opens slightly. He looks at me in utter surprise and I can’t help but laugh.
The openness and stillness our meditation cultivates is the kind needed to be good friends and colleagues. It’s practice being able to register the actions, words, and emotions of others in an encounter, rather than focusing on one’s own inner world, emotions, and thoughts. One of the limitations many meditators encounter is the difficulty transferring the same grounded bliss from the mat to the boardroom: the tendency is to default right back to our same old selves upon entering into the magnetic field of a given epistemological network and context. I’ve felt this frustration, and wondered if all the morning practice would ever amount to transformative change at work and in the rest of my life. There’s a good case to be made that meditating with someone else is better practice for the entangled consciousness we experience with others. It’s awkward at first, but it’s where the real work takes place. Almost like the initial resistance to taking an improv class that can go on to work wonders for one’s ability to act bravely and brazenly in other areas of life. I’d love to transform myself into a blank and open vessel, always open to others, able to see them for who they are, with strengths and weaknesses and beauty and blemishes, and to help them grow with equanimity. To register every last detail of every encounter and replicate the details in my mind. It’s a work in progress.[8]
Seeing the Details
Meditating with Mihnea gives me time to study him with the minute gaze of an entomologist. I study the curve of his chin, the two little freckles near his right eye (left-looking to me as we face one another), the curve of the bottom of his earlobes into the side of his face (he has attached earlobes like Clint Eastwood), the distribution of grey and black beard hairs at different lengths depending on when he last shaved, the shape of his lips, the chappedness of his lips at any given time, the puncture a single beard hair through the center of his bottom lip, stains on the side of his teeth, the odor of his breath (so often hinting tangerine oil), the smell of love in his veins and through his cartilage, the aura that emanates from behind his neck, like a halo on a Fra Angelico fresco, the furrow of his brow, the uneven distribution of his forehead pores, the even distribution of his skin melatonin, the precision of his hair line depending when he last got a haircut, the depth of the inlay into his spine in his lower back. It can go on to infinity, confirming the glorious skepticism of all that is there to be known.
One of the most beautiful and sensual films about the precise gaze of the entomologist is Hiroshi Teshigahara’s Woman of the Dunes (1964). At first trapped in a sand dune with an alienating woman, the protagonist comes to cultivate a new obsession extracting water from the sand.
I like to pay particular attention to the details of Mihnea’s eyes, and see different things every time. Their colors are enormously complex: he has hazel eyes with brown concentrated near the pupils (which sometimes dilate or constrict extremely rapidly after he returns his head back to look at me after bending his neck, only to encounter the shock of the bright lights above), followed by rays of green that eventually give to violet lining around the iris. His sclera tend to be bloodshot in the evening, which is when we tend to sit on weekdays. His eyes are galaxies, Leibnizian monads whose lines narrate a universe’s worth of history. And every time we meditate, water collects at the bottom of Mihnea’s eyes. I always wonder if it harkens tears. Sometimes it does. When it does, and I ask him afterwards why he cried, he says it is to wash away my pain.
One time I examined his tears. We didn’t let them keep us from meditating. We stayed silent. The tears were slow to fall, and collected in concave meniscuses like water in a glass. They hung in suspension, stopping time in the dense event horizon of his hands laced behind my back. Finally they fell. They fell down his cheek and dampened the two freckles under his right eye. I wiped away the rivulets with the pad of my index fingers, reabsorbing the pain he felt for me as we sat.
Just different, this time.
[1] I immediately bought and devoured Rovelli’s The Order of Time after hearing him on the On Being podcast. The book inspired this post. I got my mom a copy for Christmas and learned that my dad loved it after speaking with him on a recent phone call (Mihnea and I got my dad multiple physics books for Christmas, but didn’t think to get him this one. My dad appreciates lyricism, however, so I’m not surprised he loved it too). The book’s lyrical style inspired me: it gave me license to incorporate my own emotionality into the book I thought I was going to write about machine learning. Naturally, as I work on the book, the subject matter has changed slightly. I’m still in this purgatorial space where it’s trying to figure out its identity and is currently a gangly teenager with braces experimenting with different genders. Anxiety doesn’t help much and my dear friend reason-simulating-excuses likes to do pull-ups near my right ear over my right shoulder, whispering that this is character building, reminding me that wrestling with the content is the only way to write something worth reading. She is a rascal.
[2] Perhaps my most meaningful experience at integrate.ai was my weekly meditation session with Katharine Marek. Our meditation club started off much larger. In the first session, a whole slew of us sat together in a glass-exposed room at the WeWork offices at Yonge and Bloor and did our best to concentrate and focus in the mid afternoon as passersby buzzed by like worker bees. Participation fell like lemmings off a cliff. Shradha Mittal staid with us for a few more mornings, but she only worked part-time so the habits weren’t regular. It ended up being just me and Katharine. And it was marvelous. As it was just the two of us, we could begin each session sharing our worries, doubts, anxieties, emotions, thoughts. She shared with me and I shared with her. I’d teach her different techniques, mindfulness one day, metta the next, to expose her to various kinds of meditation and let her pick which one stuck. Ever suffering from misophonia (a byproduct of being highly sensitive and anxious), I’d do my best to ignore the sound of Yevgeniy Kissin tapping his spoon on a ceramic bowl as he ate a bowl of oatmeal like clockwork at the same time every morning (it didn’t help that I knew exactly when the clinking would start; Yev knows this and knows I love him). Katharine would smirk with joy at the oddity. Being with her reminded me of the course I taught at Stanford that had only one student, the magnificent Josefina Massot. We read Milton and Hobbes and Rousseau and Kleist like two Renaissance scholars sharing ideas. Josefina also had episodes of depression, and we supported one another through the quarter, teacher loving student loving teacher. I live for these experiences and vow to keep the details alive through frequent remembrance.
[3] I’m a fan of long podcasts interviews. Tim Ferriss’s interview with Jack Kornfield, for example, is 03:02:03. I don’t feel any need to consume content within a window of time. To have a book end and have a thought be quick and compact like a teeshirt we can tidily fold and tuck away into a drawer. I listen to podcasts like I read books: I read, stop, bookmark the page, and pick up where I left off. The assumption that content should be easily digestible is patronizing. Just noticing while writing this that we use food metaphors for content, we consume and digest words. I may the odd man out here, as I heard from others who self-identify as productive, busy, important executives that they want their learning to churned and scoped down like the tasks they jump around from in their day-to-day lives.
[4] It’s in The Phaedrus that Plato references that the technology of writing may have a deleterious impact on human memory (for if we outsource memory to writing, we won’t exercise the capability and it will fade over time). It’s a good reminder to see that there’s long-standing fear about how some new technology will lead to our gradual degradation into use automata. I tend to think this stems from a lack of imagination and proclivities towards fear: we ground our predictions in what the future will look like after some change in the context of what we see and know today. The wonderful thing about participating in non-linear and complex systems is that they are complex and can react in ways we don’t predict in advance. Tim Harford does an excellent job showing the complex entanglement of social developments from new technologies and inventions in 50 Inventions That Shaped the Modern Economy, illustrating, for example, the relationship between birth control and gender equality in the workplace. Plato feared writing. Some people fear AI. I tend to most fear, based on my own experience, distraction-inducing technologies, even something as simple as the notifications on our devices. Notifications annihilate coherence, which Mihnea and I both prize. He recently shared that enough Generation Zsters use closed captioning to keep their attention focused on movies and videos that it’s capturing media attention.
[5] I wanted to show a picture of pranayama finger positions but everything I found looked ridiculous. Here, for example, is the wikiHow picture. In my brief but fruitless search, I also learned that Hilary Clinton swore by pranayama techniques to calm herself in the aftermath of the 2016 presidential election. Naturally, this is only interesting because it’s Hilary Clinton, both because of the star factor (our curiosity to know famous people’s habits, as if this where some sort of privileged knowledge; the phenomenon of completely disregarding privacy when it comes to famous people is bizarre. Is it cultivated by their constant visibility in the media or an intrinsic default of human group psychology and dominance hierarchies?) and the surprise factor thinking about Hilary behaving this way. Then again, Jeb Bush was on a paleo diet leading up to the elections. Politicians are people, too.
[6] Three very smart Johns I know, John Hall (CEO of Intapp), John Frankel (Managing Partner at ffVC), and John Deighton (Professor at Harvard Business School), all believe that technology moves in cycles between centralization and decentralization: the mainframe was followed by the client-server, which, after virtualization, was followed by the public cloud, which, now that we’re getting queasy about the power of so much centralized data and have a network of mobile devices and IoT-enabled cars and toasters and things hopping around the world, will be followed by decentralization once more once we can get GPUs and TPUs small enough to work well on mobile devices. We are very, very close. Distributed ledgers and databases are also harbingers of what’s to come. I’m keen to know what it means for the ideological superstructures on top of the material backbone of society. Or maybe information technologies alter some of Marx’s axioms? It’s definitely the case that we need a new economic model for data-powered software, the same way SaaS subscription business models were created for the cloud.
[7] It’s funny that Bertrand Russell decided to embody the first-order logic paradox that yielded Gödel’s incompleteness theorem as the barber paradox: “The barber is the “one who shaves all those, and those only, who do not shave themselves.” The question is, does the barber shave himself?” I haven’t seen a lot recently in the AI community grounded consciousness on recursive loops the way Hofstadter did back in the days of symbolic AI as canonized in Gödel, Escher, Bach. As intimated in this post, Mihnea and I are both after an articulation of minds as entangled phenomenon, selves not as static brains in vats but as dynamic and complex systems entangled in different social contexts.
[8] Mihnea is a priest of language. He ends his book Inside Man with a gesture towards the communicative ethics that guide his internal dialogues as much as his dialogues with others. He cultivates minute precision in language in part because generalities and abstractions leave room for an interlocutor to extend a comment or criticism to encompass their entire being: “try tilting your wrist a little to the right when you swing the tennis racket” turns into “you suck at tennis and that means you can’t learn anything new and that means your career is ruined and that means you’re a pathetic failure, oh yeah, and that also means I think you’re a pathetic failure.” He’s helped me come to understand how dangerous it can be when others cannot refer to a particular behavior or activity when they provide feedback, and instead have couched multiple vague impressions into a narrative that leads to nothing but harm to a student or teammate.
The featured image is the Contemplative Bodhisattva, National Treasure of Korea No. 83. Insured for an estimated 50 billion won, it is the most expensive Korean national treasure. The semi-seated figure is Maitreya, a bodhisattva (someone working towards Buddhahood, but who has not yet attained it) prophesied to appear on Earth, achieve enlightenment, and teach the dharma, the way of being in line with the right order of the universe. I learned how remarkable this statue is when I attempted to crop the photo to make the proportions fit more nicely into the frame of my posts (I prefer square images or flat images with narrow heights, rather than long upright rectangles). It lost its aura when I cropped it, There is a majestic balance between the narrow, smooth lines of Maitreya’s chest, the silent grace of his necklaces, and the textured flow of the draping cloth. His bent knee carries forth the line sketched by the upturned rim of cloth upon his seat. He’s leaning forward slightly (apparent when you view the figure in profile) and it’s as if the lower half is required to cradle his balance and keep the painting unified and whole. The chipped enamel reminds me of the skin of yellow beats, shedding ground dirt to canvass concentric circles that beam inside.
Not every event in your life has had profound significance for you. There are a few, however, that I would consider likely to have changed things for you, to have illuminated your path. Ordinarily, events that change our path are impersonal affairs, and yet are extremely personal. - Don Juan Matus, a (potentially fictional) Yaqui shaman from Mexico
The windowless classroom was dark. We were sitting around a rectangular table looking at a projection of Rembrandt’s Syndics of the Drapers’ Guild. Seated opposite the projector, I could see student faces punctuate the darkness, arching noses and blunt hair cuts carving topography through the reddish glow.
“What do you see?”
Barbara Stafford’s voice had the crackly timbre of a Pablo Casals record and her burnt-orange hair was bi-toned like a Rothko painting. She wore downtown attire, suits far too elegant for campus with collars that added movement and texture to otherwise flat lines. We were in her Art History 101 seminar, an option for University of Chicago undergrads to satisfy a core arts & humanities requirement. Most of us were curious about art but wouldn’t major in art history; some wished they were elsewhere. Barbara knew this.
“A sort of darkness and suspicion,” offered one student.
“Smugness in the projection of power,” added another.
“But those are interpretations! What about the men that makes them look suspicious or smug? Start with concrete details. What do you see?”
No one spoke. For some reason this was really hard. It didn’t occur to anyone to say something as literal as “I see a group of men, most of whom have long, curly, light-brown hair, in black robes with wide-brimmed tall black hats sitting around a table draped with a red Persian rug in the daytime.” Too obvious, like posing a basic question about a math proof (where someone else inevitably poses the question and the professor inevitably remarks how great a question it is to our curious but proud dismay). We couldn’t see the painting because we were too busy searching for a way of seeing that would show others how smart we were.
“Katie, you’re our resident fashionista. What strikes you about their clothing?”
Adrenaline surged. I felt my face glow in the reddish hue of the projector, watched others’ faces turn to look at mine, felt a mixture of embarrassment at being tokenized as the student who cared most about clothes and appearance and pride that Barbara found something worth noticing, in particular given her own evident attention to style. Clothes weren’t just clothes for me: they were both art and protection. The prospect of wearing the same J Crew sweater or Seven jeans as another girl had been cruelly beaten out of me in seventh grade, when a queen mean girl snidely asked, in chemistry class, if I knew that she had worn the exact same salmon-colored Gap button-down crew neck cotton sweater, simply in the cream color, the day before. My mom had gotten me the sweater. All moms got their kids Gap sweaters in those days. The insinuation was preposterous but stung like a wasp: henceforth I felt a tinge of awkwardness upon noticing another woman wearing an article of clothing I owned. In those days I wore long ribbons in my ponytails to make my hair seem longer than it was, like extensions. I often wore scarves, having admired the elegance of Spanish women tucking silk scarves under propped collared shirts during my senior year of high school abroad in Burgos, Spain. Material hung everywhere around me. I liked how it moved in the wind and encircled me in the grace I feared I lacked.
“I guess the collars draw your attention. The three guys sitting down have longer collars. They look like bibs. The collar of the guy in the middle is tied tight, barely any space between the folds. A silver locket emerges from underneath. The collars of the two men to his left (and our right) billow more, they’re bunchy, as if those two weren’t so anal retentive when they get dressed in the morning. They also have kinder expressions, especially the guy directly to the left of the one in the center. And then it’s as if the collars of the men standing to the right had too much starch. They’re propped up and overly stiff, caricature stiff. You almost get the feeling Rembrandt added extra air to these puffed up collars to make a statement about the men having their portrait done. Like, someone who had taste and grace wouldn’t have a collar that was so visibly puffy and stiff. Also, the guy in the back doesn’t have a hat like the others.”
Barbara glowed. I’d given her something to work with, a constraint from which to create a world. I felt like I’d just finished a performance, felt the adrenaline subside as students’ turned their heads back to face the painting again, shifted their attention to the next question, the next comment, the next brush stroke in Syndics of the Drapers’ Guild.
After a few more turns goading students to describe the painting, Barbara stepped out of her role as Socrates and told us about the painting’s historical context. I don’t remember what she said or how she looked when she said it. I don’t remember every class with her. I do remember a homework assignment she gave inspired by André Breton’s objet trouvé, a surrealist technique designed to get outside our standard habits of perception, to let objects we wouldn’t normally see pop into our attention. I wrote about my roommate’s black high-heeled shoes and Barbara could tell I was reading Nietzsche’s Birth of Tragedy because I kept referencing Apollo and Dionysus, godheads for constructive reason and destructive passion, entropy pulling us ever to our demise.[1] I also remember a class where we studied Cindy Sherman photos, in particular her self portraits as Caravaggio’s Bacchus and her film still from Hitchcock’s Vertigo. We took a trip to the Chicago Art Institute and looked at few paintings together. Barbara advised us never to use the handheld audio guides as they would pollute our vision. We had to learn how to trust ourselves and observe the world like scientists.
Cindy Sherman’s Untitled #224, styled after Caravaggio’s BacchusCindy Sherman’s Untitled Film Still 21, styled after Hitchcock’s Vertigo
In the fourth paragraph of the bio on her personal website, Barbara says that “she likes to touch the earth without gloves.” She explains that this means she doesn’t just write about art and how we perceive images, but also “embodies her ideas in exhibitions.”
I interpret the sentence differently. To touch the earth without gloves is to see the details, to pull back the covers of intentionality and watch as if no one were watching. Arts and humanities departments are struggling to stay relevant in an age where we value computer science, mathematics, and engineering. But Barbara didn’t teach us about art. She taught us how to see, taught us how to make room for the phenomenon in front of us. Paintings like Rembrandt’s Syndics of the Drapers’ Guild were a convenient vehicle for training skills that can be transferred and used elsewhere, skills which, I’d argue, are not only relevant but essential to being strong leaders, exacting scientists, and respectful colleagues. No matter what field we work in, we must all work all the time to notice our cognitive biases, the ever-present mind ghosts that distort our vision. We must make room for observation. Encounter others as they are, hear them, remember their words, watch how their emotions speak through the slight curl of their lips and the upturned arch of their eyebrows. Great software needs more than just engineering and science: it needs designers who observe the world to identify features worth building.
I am indebted to Barbara for teaching me how to see. She is integral to the success I’ve had in my career in technology.
A picture that captures what I remember about Barbara
Of all the memories I could share about my college experience, why share this one? Why do I remember it so vividly? What makes this memory profound?
I recently read Carlos Casteñeda’s The Active Side of Infinity and resonated with book’s premise as “a collection of memorable events” Casteñeda recounts as an exercise to become a warrior-traveler like the shamans who lived in Mexico in ancient times. Don Juan Matus, a (potentially fictional) Yaqui shaman who plays the character of Casteñeda’s guru in most of his work, considers the album “an exercise in discipline and impartiality…an act of war.” On his first pass, Casteñeda picks out memories he assumes should be important in shaping him as an individual, events like getting accepted to the anthropology program at UCLA or almost marrying a Kay Condor. Don Juan dismisses them as “a pile of nonsense,” noting they are focused on his own emotions rather than being “impersonal affairs” that are nonetheless “extremely personal.”
The first story Casteñeda tells that don Juan deems fit for a warrior-traveler is about Madame Ludmilla, “a round, short woman with bleached-blond hair…wearing a a red silk robe with feathery, flouncy sleeves and red slippers with furry balls on top” who performs a grotesque strip tease called “figures in front of a mirror.” The visuals remind me of dream sequence from a Fellini movie, filled with the voluptuousness of wrinkled skin and sagging breasts and the brute force of the carnivalesque. Casteñeda’s writing is noticeably better when he starts telling Madame Ludmilla’s story: there’s more detail, more life. We can picture others, smell the putrid stench of dried vomit behind the bar, relive the event with Casteñeda and recognize a truth in what he’s lived, not because we’ve had the exact same experience, but because we’ve experienced something similar enough to meet him in the overtones. “What makes [this story] different and memorable,” explains don Juan, “is that it touches every one of us human beings, not just you.”
This is how I imagined Madame Ludmilla, as depicted in Fellini’s 8 1/2. As don Juan says, we are all “senseless figures in front of a mirror.”
Don Juan calls this war because it requires discipline to see the world this way. Day in and day out, structures around us bid us to focus our attention on ourselves, to view the world through the prism of self-improvement and self-criticism: What do I want from this encounter? What does he think of me? When I took that action, did she react with admiration or contempt? Is she thinner than I am? Look at her thighs in those pants-if I keep eating desserts they way I do, my thighs will start to look like that too. I’ve fully adopted the growth mindset and am currently working on empathy: in that last encounter, I would only give myself a 4/10 on my empathy scale. But don’t you see that I’m an ESFJ? You have to understand my actions through the prism of my self-revealed personality guide! It’s as if we live in a self-development petri dish, where experiences with others are instruments and experiments to make us better. Everything we live, everyone we meet, and everything we remember gets distorted through a particular analytical prism: we don’t see and love others, we see them through the comparative machine of the pre-frontal cortex, comparing, contrasting, categorizing, evaluating them through the prism of how they help or hinder our ability to become the future self we aspire to become.
Warrior-travelers like don Juan fight against this tendency. Collecting an album of memorable events is a exercise in learning how to live differently, to change how we interpret our memories and first-person experiences. As non-warriors, we view memories as scars, events that shape our personality and make us who we are. As warriors, we view ourselves as instruments and vessels to perceive truths worth sharing, where events just so happen to happen to us so we can feel them deeply enough and experience the minute details required to share vivid details with others. Warriors are instruments of the universe, vessels for the universe to come to know itself. We can’t distort what others feel because we want them to like us or act a certain way because of us: we have to see others for who they are, make space for negative and positive emotions. What matters isn’t that we improve or succeed, but that we increase the range of what’s perceivable. Only then can we transmit information with the force required to heal or inspire. Only then are we fearless.
Don Juan’s ways of seeing and being weren’t all new to me (although there were some crazy ideas of viewing people as floating energy balls). There are sprinklings of my quest to live outside the self in many posts on the blog. Rather, TheActive Side of Infinity helped me clarify why I share first-person stories in the first place. I don’t write to tell the world about myself or share experiences in an effort to shape my identity. This isn’t catharsis. I write to be a vessel, a warrior-traveller. To share what I felt and saw and smelled and touched as I lived experiences that I didn’t know would be important at the time but that have managed to stick around, like Argos, always coming back, somehow catalyzing feelings of love and gratitude as intense today as they were when I first experienced them. To use my experiences to illustrate things we are all likely to experience in some way or another. To turn memories into stories worth sharing, with details concrete enough that you, reader, can feel them, can relate to them, and understand a truth that, ill-defined and informal though it may be, is searing in its beauty.
This post features two excerpts from my warrior-traveler album, both from my time as an undergraduate at the University of Chicago. I ask myself: if I were speaking to someone for the first time and they asked me to tell them about myself, starting in college, would I share these memories? Likely not. But it’s a worthwhile to wonder if doing so might change the world for the good.
When I attended the University of Chicago, very few professors gave students long reading assignments for the first class. Some would share a syllabus, others would circulate a few questions to get us thinking. No one except Loren Kruger expected us to read half of Anna Karenina and be prepared to discuss Tolstoy’s use of literary from to illustrate 19th-century Russian class structures and ideology.
Loren was tall and big boned. A South African, she once commented on J.M. Coetzee’s startling ability to wield power through silence. She shared his quiet intensity, demanded such rigor and precision in her own work that couldn’t but demand it from others. The tiredness of the old world laced her eyes, but her work was about resistance; she wrote about Brecht breaking boundaries in theater, art as an iron-hot rod that could shed society’s tired skin and make room for something new. She thought email destroyed intimacy because the virtual distance emboldened students to reach out far more frequently than when they had to brave a face-to-face encounter. About fifteen students attended the first class. By the third class, there were only three of us. With two teaching assistants (a French speaker and a German speaker), the student:teacher ratio became one:one.[2]
A picture that captures what I remember about Loren
Loren intimated me, too. The culture at the University of Chicago favored critical thinking and debate, so I never worried about whether my comments would offend others or come off as bitchy (at Stanford, sadly, this was often the case). I did worry about whether my ideas made sense. Being the most talkative student in a class of three meant I was constantly exposed in Loren’s class, subjecting myself to feedback and criticism. She criticized openly and copiously, pushing us for precision, depth, insight. It was tough love.
The first thing Loren taught me was the importance of providing concrete examples to test how well I understood a theory. We were reading Karl Marx, either The German Ideology or the first volume of Das Kapital.[3] I confidently answered Loren’s questions about the text, reshuffling Marx’s words or restating what he’d written in my own words. She then asked me to provide a real-world example of one of his theories. I was blank. Had no clue how to answer. I’d grown accustomed to thinking at a level of abstraction, riding text like a surfer rides the top of a wave without grounding the thoughts in particular examples my mind could concretely imagine.[4] The gap humbled me, changed how I test whether I understand something. This happens to be a critical skill in my current work in technology, given how much marketing and business language is high-level and general: teams think they are thinking the same thing, only to realize that with a little more detail they are totally misaligned.
We wrote midterm papers. I don’t remember what I wrote about but do remember opening the email with the grade and her comments, laptop propped on my knees and back resting against the powder-blue wall in my bedroom off the kitchen in the apartment on Woodlawn Avenue. B+. “You are capable of much more than this.” Up rang my old friend imposture syndrome: no, I’m not, what looks like eloquence in class is just a sham, she’s going to realize I’m not what she thinks I am, useless, stupid, I’ll never be able to translate what I can say into writing. I don’t know how. Tucked behind the fiddling furies whispered the faint voice of reason: You do remember that you wrote your paper in a few hours, right? That you were rushing around after the house was robbed for the second time and you had to move?
Before writing our final papers, we had to submit and receive feedback on a formal prospectus rather than just picking a topic. We’d read Franz Fanon’s The Wretched of the Earth and I worked with Dustin (my personal TA) to craft a prospectus analyzing Gillo Pontecorvo’s Battle of Algiers in light of some of Fanon’s descriptions of the experience of colonialism.[7]
Once again, Loren critiqued it harshly. This time I panicked. I didn’t want to disappoint her again, didn’t want the paper to confirm to both of us that I was useless, incompetent, unable to distill my thinking into clear and cogent writing. The topic was new to me and out of my comfort zone: I wasn’t an expert in negritude and or post-colonial critical theory. I wrote her a desperate email suggesting I write about Baudelaire and Adorno instead. I’d written many successful papers about French Romanticism and Symbolism and was on safer ground.
Her response to my anxious plea was one of the more meaningful interactions I’ve ever had with a professor.
Katie, stop thinking about what you’re going to write and just write. You are spending far too much energy worrying about your topic and what you might or might not produce. I am more than confident you are capable of writing something marvelous about the subject you’ve chosen. You’ve demonstrated that to me over the quarter. My critiques of your prospectus were intended to help you refine your thinking, not push you to work on something else. Just work!
I smiled a sigh of relief. No professor had ever said that to me before. Loren had paid attention, noticed symptoms of anxiety but didn’t placate or coddle me. She remained tough because she believed I could improve. Braved the mania. This interaction has had a longer-lasting impact on me than anything I learned about the subject matter in her class. I can call it to mind today, in an entirely different context of activity, to galvanize myself to get started when I’m anxious about a project at work.
The happiest moments writing my final paper about the Battle of Algiers were the moments describing what I saw in the film. I love using words to replay sequences of stills, love interpreting how the placement of objects or people in a still creates an emotional effect. My knack for doing so stems back to what I learned in Art History 101. I think I got an A on the paper. I don’t remember or care. What stays with me is my gratitude to Loren for not letting me give up, and the clear evidence she cared enough about me to put in the work required to help me grow.
[1] This isn’t the first time things I learned in Barbara’s class have made it into my blog. The objet trouvé exercise inspired a former blog post.
[2] I ended up having my own private teaching assistant, a French PhD named Dustin. He told me any self-respecting comparative literature scholar could read and speak both French and German fluently, inspiring me to spend the following year in Germany.
[3] I picked up my copy of The Marx-Engels Reader (MER) to remember what text we read in Loren’s class. I first read other texts in the MER in Classics of Social and Political Thought, a social sciences survey course that I took to fulfilled a core requirement (similar to Barbara’s Art History 101) my sophomore year. One thing that leads me to believe we read The German Ideology or volume one of Das Kapital in Loren’s class is the difference in my handwriting between years two and four of college. In year two, my handwriting still had round playfulness to it. The letters are young and joyful, but look like they took a long time to write. I remember noticing that my math professors all seemed to adopt a more compact and efficient font when they wrote proofs on the chalkboard: the a’s were totally sans-serif, loopless. Letters were small. They occupied little space and did what they could not to draw attention to themselves so the thinker could focus on the logic and ideas they represented. I liked those selfless a’s and deliberately changed my handwriting to imitate my math professors. The outcome shows in my MER. I apparently used to like check marks to signal something important: they show up next to straight lines illuminating passages to come back to. A few great notes in the margins are: “Hegelian->Too preoccupied w/ spirit coming to itself at basis…remember we are in (in is circled) world of material” and “Inauthenticity->Displacement of authentic action b/c always work for later (university/alienation w/ me?)”
[4] There has to be a ton of analytic philosophy ink spilled on this question, but it’s interesting to think about what kinds of thinking is advanced by pure formalisms that would be hampered by ties to concrete, imaginable referents and what kinds of thinking degrade into senseless mumbo jumbo without ties to concrete, imaginable referents. Marketing language and politically correct platitudes definitely fall into category two. One contemporary symptom of not knowing what one’s talking about is the abuse of the demonstrative adjective that. Interestingly enough, such demonstrative abusers never talk about thises, they only talk about thats.This may be used emphatically and demonstratively in a Twitter or Facebook conversation: when someone wholeheartedly supports a comment, critique, or example of some point, they’ll write This as a stand-alone sentence with super-demonstrative reference power, power strong enough to encompass the entire statement made before it. That’s actually ok. It’s referring to one thing, the thing stated just above it. It’s dramatic but points to something the listener/reader can also point to. The problem with the abused that is that it starts to refer to a general class of things that are assumed, in the context of the conversation, to have some mutually understood functional value: “To successfully negotiate the meeting, you have to have that presentation.” “Have that conversation — it’s the only way to support your D&I efforts!” Here, the listener cannot imagine any particular that that these words denote. The speaker is pointing to a class of objects she assumes the listener is also familiar with and agrees exist. A conversation about what? A presentation that looks like what? There are so many different kinds and qualities of conversations or presentations that could fit the bill. I hear this used all the time and cringe a little inside every time. I’m curious to know if others have the same reaction I do, or if I should update my grammar police to accept what has become common usage. Leibniz, on the other hand, was an early modern staunch defender of cogitatio caeca (Latin for blind thought), which referred to our ability to calculate and manipulate formal symbols and create truthful statements without requiring the halting step of imagining the concrete objects these symbols refer to. This, he argued against conservatives like Thomas Hobbes, was crucial to advance mathematics. There are structural similarities in the current debates about explainability of machine learning algorithms, even though that which is imagined or understood may lie on a different epistemological, ontological, and logical plane.
[5] People tell me that one reason they like my talks about machine learning is that I use a lot of examples to help them understand abstract concepts. Many talks are structured like this one, where I walk an audience through the decisions they would have to make as a cross-functional team collaborating on a machine learning application. The example comes from a project former colleagues worked on. I realized over the last couple of years that no matter how much I like public speaking, I am horrified by the prospect of specializing in speaking or thought leadership and not being actively engaged in the nitty-gritty, day-to-day work of building systems and observing first-person how people interact with them. I believe the existential horror stems from my deep-seated beliefs about language and communication, in my deep-seated discomfort with words that don’t refer to anything. Diving into this would be worthwhile: there’s a big difference between the fictional imagination, the ability to bring to life the concrete particularity of something or someone that doesn’t exist, and the vagueness of generalities lacking reference. The second does harm and breeds stereotypes. The first is not only potent in the realm of fiction, but, as my fiancé Mihnea is helping me understand, may well be one of the master skills of the entrepreneur and executive. Getting people aligned and galvanized around a vision can only occur if that vision is concrete, compelling, and believable. An imaginable state of the world we can all inhabit, even if it doesn’t exist yet. A tractable as if that has the power to influence what we do and how we behave today so as to encourage its creation and possibility.[6]
[6] I believe this is the first time I’ve had a footnote referring to another footnote (I did play around with writing an incorrigibly long photo caption in Analogue Repeaters). Funny this ties to the footnote just above (hello there, dear footnote!) and even funnier that footnote 4 is about demonstrative reference, including the this discursive reference. But it’s seriously another thought so I felt it merited it’s own footnote as opposed to being the second half of footnote 5. When I sat down to write this post, I originally planned to write about the curious and incredible potency of imagined future states as tools to direct action in the present. I’ve been thinking about this conceptual structure for a long time, having written about it in the context of seventeenth-century French philosophy, math, and literature in my dissertation. The structure has been around since the Greeks (Aristotle references it in Book III of the Nicomachean Ethics) and is used in startup culture today. I started writing a post on the topic in August, 2018. Here’s the text I found in the incomplete draft when I reopened it a few days ago:
A goal is a thinking tool.
A good goal motivates through structured rewards. It keeps people focused on an outcome, helps them prioritize actions and say no to things, and stretches them to work harder than they would otherwise. Wise people say that a good goal should be about 80% achievable. Wise leaders make time reward and recognize inputs and outputs.
A great goal reframes what’s possible. It is moonshot and requires the suspension of disbelief, the willingness to quiet all the we can’ts and believe something surreal, to sacrifice realism and make room for excellence. It assumes a future outcome that is so outlandish, so bold, that when you work backwards through the series of steps required to achieve it, you start to do great things you wouldn’t have done otherwise. Fools say that it doesn’t matter if you never come close to realizing a great goal, because the very act of supposing it could be possible and reorienting your compass has already resulted in concrete progress towards a slightly more reasonable but still way above average outcome.
Good goals create outcomes. Great goals create legacies.
This text alienates me. It reminds me of an inspirational business book: the syncopation and pace seem geared to stir pathos and excitement. How curious that the self evolves so quickly, that the I looking back on the same I’s creations of a few months ago feels like she is observing a stranger, someone speaking a different language and inhabiting a different world. But of course that’s the case. Of course being in a different environment shapes how one thinks and what one sees. And the lesson here is not one of fear around instability of character: it’s one that underlines to crucial importance of context, the crucial importance of taking care to select our surroundings so we fill our brains with thoughts and words that shape a world we find beautiful, a world we can call home. The other point of this footnote is a comment on the creative process. Readers may have noted the quotation from Pascal that accompanies all my posts: “The last thing one settles in writing a book is what one should put in first.” The joy of writing, for me, as for Mihnea and Kevin Kelly and many others, lies in unpacking an intuition, sitting down in front of a silent wall and a silent world to try to better understand something. I’m happiest when, writing fast, bad, and wrong to give my thoughts space to unfurl, I discover something I wouldn’t have discovered had I not written. Writing creates these thoughts. It’s possible they lie dormant with potential inside the dense snarl of an intuition and possible they wouldn’t have existed otherwise. Topic for another post. With this post, I originally intended to use the anecdote about Stafford’s class to show the importance of using concrete details, to illustrate how training in art history may actually be great training for the tasks of a leader and CEO. But as my mind circled around the structure that would make this kind of intro make sense, I was called to write about Casteñeda, pulled there by my emotions and how meaningful these memories of Barbara and Loren felt. I changed the topic. Followed the path my emotions carved for me. The process was painful and anxiety-inducing. But it also felt like the kind of struggle I wanted to undertake and live through in the service of writing something worth reading, the purpose of my blog.
[7] About six months ago, I learned that an Algerian taxi driver in Montréal was the nephew of Ali La Pointe, the revolutionary martyr hero in Battle of Algiers. It’s possible he was lying, but he was delighted by the fact that I’d seen and loved the film and told me about the heroic deeds of another uncle who didn’t have the same iconic stardom as Ali. Later that evening I attended a dinner hosted by Element AI and couldn’t help but tell Yoshua Bengio about the incredible conversation I had in the taxi cab. He looked at me with confusion and discomfort, put somewhat out of place and mind by my not accommodating the customary rules of conversation with acquaintances.
The featured image is the Syndics of the Drapers’ Guild, which Rembrandt painted in 1662. The assembled drapers assess the quality of different weaves and cloths, presumably, here, assessing the quality of the red rug splayed over the table. In Ways of Seeing, John Berger writes about how oil paintings signified social status in the early modern period. Having your portrait done showed you’d made it, the way driving a Porsche around town would do so today. When I mentioned that the collars seemed a little out of place, Barbara Stafford found the detail relevant precisely because of the plausibility that Rembrandt was including hints of disdain and critique in the commissioned portraits, mocking both his subjects and his dependence on them to get by.
I did my first TED Talk in October, part of a TED Salon in New York City. I’ve thanked Alex Moura, TED’s technology coordinator, for inviting me and coaching me through the process, but it never hurts to say thanks multiple times. I’d also like to extend thanks to Cloe Sasha, Crawford Hunt, Corey Hajim, and the NYC production and makeup crew. As I wrote about last summer, stage crews are pre-talk angels that help me metabolize anxiety through humor, emotion, and the simple joy of connecting with another individual. At the TED headquarters, the crew gave me a detailed run down of how the audio and video systems work, how they edit raw recordings, how different speakers behave before talks, and why they decided to be in their field. I learned something. I can precisely recall how the production manager laced his naturally spindly, Woody-Allenesque voice with a practiced hint of care, cradling the speakers with confidence before we took the stage. His presence exuded joy through focused concentration, the joy of a professional who does his work with integrity.
Here’s the talk. My hands look so theatrical because I normally release nervous energy as kinetic energy by pacing back and forth. TED taught me that’s a chump move that distracts the audience: a great presenter stays put so people can focus. The words, story, tone, pitch, dynamics, emotions, and face cohere into an impression that draws people in because multiple parts of their brain unite to say “Pay attention! Valuable stuff is coming your way!”[1] I have some work to do before I master that. When I gave the talk, my mind’s albatross meta voice was clamoring “Stay put! Resist the urge! Stop doing that! In channel 8 you’re at chunk 3 of your AI talk right? Enter spam filter to illustrate the difference between Boolean rules and a learned classifier…what’s that person in row 2 thinking? Is the nod…yeah, seems ok but then again that eyebrow…interference from channel 18 your fucking vest isn’t hooked…shit…” resulting in moments in my talk where my gestures look like moves from Michael Jackson’s Thriller.[2] Come to think of it, I’m often appalled by the emotions my face displays in snapshots from talks. Seeing them is stranger than hearing the sound of my voice on a recording. My emotional landscape shifts quickly, perhaps quickly enough that the disgust of one femtosecond resolves into content in the next, keeping the audience engaged as time flows but leading to alien distortions when time freezes.
As I argued in my dissertation (partially summarized here), I’m a fan of Descartes’ pedagogical opinion that we learn more from understanding how someone discovered something-and then challenging ourselves to put this process into practice so we can come to discover something on our own-than we do from studying the finished product. I therefore figured it may be useful for a few readers if I shared how I wrote this talk and a few of the lessons I learned along the way.
Like Edgar Allen Poe in his Philosophy of Composition, I started by thinking about the intention of my talk. Like Poe, I wanted to write a talk “that should suit at once the popular and the critical taste.” This was TED, after all, not an academic lecture at the University of Toronto. I needed an introduction to AI that would be accessible to a general audience but had enough rigor to merit respect from experts in the field. I often strive to speak and write according to this intention, as I find saying something in plain old English pressure tests how well I understand something. Poe then talks about the length of a poem, wanting something that can be read in one sitting. Most of the time, the venue tells you how long to speak, and it’s way harder to write an informative 10-minute talk than a cohesive 45-minute talk. TED gave me a constraint of 12 minutes. So my task was to communicate one useful insight about AI that could change how a non-expert thinks about the term, to shows this one insight a few different ways in 12 minutes, and to do this while staving off the inevitable grimaces from experts.
Alex and I started with a brief call and landed, provisionally, on adapting a talk I gave at Startupfest in 2017. The wonderful Rebecca Croll, referred by the also wonderful Jana Eggers, invited me to speak about the future of AI. As that’s just fiction, I figured I’d own it and tell the fictional life story of one Jean-Sebastian Gagnon, a boy born the day I gave my talk. The talk pits futurism alongside nostalgia, showing how age-old coming-of-age moments, like learning about music and falling in love, are shaped by AI. He eventually realizes I’m giving a talk about him and intervenes to correct errors in my narrative. Alex suggested I adapt this to a business applying AI for the first time. I was open to it, but didn’t have a clear intuition. It sat there on the back burner of possibility.
The first idea that got me excited came to me on a run one morning through the Toronto ravines. The air was crisp with late summer haze. Limestone dust bloomed mushroom clouds that hovered, briefly, before freeing the landscape into whitewashed pastel. The flowers had peaked, each turgid petal blooming signs of eminent decay. Nearby a woman with violet grey hair that matched the color of her windbreaker and three-quarter length leggings used her leg strength to hold back a black lab who wanted nothing more than to run beside me down the widening path. With music blaring in my ears, I was brainstorming different ideas and, unsurprisingly, found myself thinking about an anecdote I frequently use ground the audience’s intuitions about AI when I open my talks. It’s a story about my friend Andrew bootstrapping a legal opinion from a database of former law student responses (I wrote about here and used to open this talk). I begin that narrative with a reference to Tim Urban’s admirable talk about procrastination. And, suddenly it hit: a TED talk within a TED talk! Recursion, crown prince of cognitive delight. “OMG that’s it! I’ll generate a TED talk by training a machine learning model on all the past TED talks! Evan Macmillan’s analysis of word frequency in all the former Data Driven talks worked well. Adapt his approach? Maybe. Or, I can recount the process of creation (meta reference not intended) to show what happens when we apply AI: show the ridiculous mistakes our model will make, show the differences between human and machine creation, grapple with the practical tradeoffs between accuracy and output, and end with a heroic message about a team bridging the different ways they see the same problem to create something of value. Awesome!” I called my parents, thrilled. Wrote slack messages to engage two of my colleagues. They were thrilled. We were off the to races, pushed by the adrenaline of discovery amplified by the endorphins of a morning run.
The joy of my mind racing, creating at a million miles an hour, provided uncanny relief. It was one of the first morning runs I’d taken in a while, after experimenting over the summer with schedule that prioritized cognitive output. As my mind is clearest between 6:00-10:00, I got to the office before 6:30 am and shifted exercise to the afternoons or evenings. I didn’t neglect my body, but deprioritized taking care of it. And in doing so, I committed the cardinal sin of Western metaphysics, fell into the Cartesian trap I myself tried to undo in my dissertation! The mistake was to think of the mind and its creations as independent from the body. Feeling my creativity surge on that morning run hit home: I thought in a way I hadn’t for months. I’ve since changed my schedule, and do make time for creative work in the morning. But I also exercise. It fuels my coherence and my generative range, the two things I value most.
I wrote to Alex at TED to tell him about my awesome idea. He was like, “yeah it’s cool, but we don’t have enough time to do that. Can you send me a draft on another topic so we can iterate together asap?”[3]
Hmpf.
Back to the drawing board.
Now, having a day job as an executive, I don’t have a lot of time to write my talks. I’ve perfected the art of putting aside two or three hours just before I have to give a presentation to tailor a talk to an audience. These kinds of constraints empower and fuel me. They don’t leave enough time for the meta critical voices to pop up and wave their scary-ass Macbeth brooms in my mind. I just produce. And, given the short time constraints, I never write my talks. Instead, I write the talk equivalent of a jazz scaffold, with pictures like a chord series upon which the musicians improvise. My talk’s logic is normally partitioned into phrases, stanzas, chunks. Another way to think about the slides are like the leitmotifs bards used in oral poetry, like the “rosy-fingered dawn” we see pop up in Homer. And I’ve done this, with reward feedback loops, for a few years. It’s ossified into a method.
A TED talk isn’t jazz. It’s like a classical concerto. You write it out in advance, practice it, and execute the harmonics, 16th notes, and double stops with virtuosic precision (I’m a violinist, so these are kinds of things I worry about). You rehearse, you don’t improvise.
That challenged me in a few ways.
First, breaking my habits spurred the nervousness we feel when we learn how to do something new. When I sat down to write a draft, my head went into talk writing mode. I did what I always do: started with an anecdote like the Andrew story, composed in chunks, represented the chunks with mnemonic devices in the form of random pictures that mean something to me and me only (until the audience sees the humorous, synthetic connection to the content). I booked an hour in my calendar to make progress on a draft but that was it: I had to move on and deliver the outcomes I’m responsible for as an executive. I just couldn’t prioritize the talk yet. So the anxiety would arise and fester and fuel itself on the constraints. I’d cobble together a few pictures and some quick notes and send them to the TED team and some friends who wanted to help review, knowing what I was sending was far from decent and near to incomprehensible.
For, of course, they couldn’t make heads or tails of the random pictures that work at a different level of meaning than the talk itself. They’d respond with compassion, do their best to gently communicate their befuddlement. It was humorously bad. And every time they expressed confusion, it eroded my confidence in the foundation of the talk. I felt a need to start over and find a new topic. I face communication foibles like this in other areas of my life and, as I work to be a better leader, try to make the time to think through the perspectives of those receiving a communication before I send it. I imagine other artists or former academic face similar challenges: we are used to prizing originality, only writing or saying something if it hasn’t been said before. In business, there’s value in repetition: saying something multiple times to increase the probability that people have heard and understood it, saying the same thing different ways in different genre and for different audiences, teaching everyone in the company to say the same thing about what you do so there is unity of message for the market. It’s against my instincts, require vigilance to preserve predictability for my teams and consistency for the market. Even for my TED talk, I felt a need to say something new. To titrate AI to its very essence, to its extraordinary quintessence. Some people coaching me said, “no, darling, they just want you to say what you’ve said a million times before. You say it so well.”
Finally, I wasn’t used to rehearsing, sharing drafts, or exposing the finished product outside the act of performance. There are two sub-points here. The first has to do with the relative comfort different people have in exposing partial ideas to others. I’m all for iteration, collaboration, getting feedback early to save time and benefit from the possible compounded creativity of multiple minds. But, as an introvert often mistaken to be an extrovert and someone trained in theoretical mathematics, I feel at ease when I have time to compose compound thoughts, with deliberately ordered, sequential parts, before sharing them with others. Showing a part is like starting a sentence and stopping midway. Not sharing early enough or quickly enough is another foible I have to constantly overcome to fit into tech culture; I believe many introverts feel similarly. Next, the pragmatic and performative context of the speech act changes it. As mentioned above, I’m a violinist, so have rehearsed and then performed many times before. But I don’t rehearse talks and really only have to myself as audience, repeating turns of phrase out loud until they hit the pithy eloquence I prize. What I didn’t know how to do was to rehearse before others. And it’s a hell of a lot harder to give a talk to one person than it is to an audience. It’s as if my self gets turned inside out when I give a talk to a single observing individual. I feel the gaze. Project what I suspect they see into a distorted clown mirror. It’s like a supreme act of objectification, all men’s eyes gazing intently on the body of Venus. Naked. Bare. Exposed. It’s 50,000 times easier to give a speech to an audience, where each individual becomes a part of an amorphous crowd, enabling me, as speaker, to speak to everyone and no one, focusing on the ideas while also picking up the emotional feedback signals acting on a different level of my brain. Learning how to collaborate, how to overcome these performative fears, was useful and something I’ll carry forward.
Midway upon this journey, finding myself within a forest dark, having lost the straightforward pathway, I came across the core idea I wanted to communicate: to succeed with AI, businesses have to invert the value of business processes from techniques to reduce variation/increase scale to techniques to learn something unique about the world that can only be learned by doing what they do. Most people think AI is about using data to enhance, automate, or improve an existing business process. That will provide sustaining innovation, but isn’t revolutionary. Things get interesting when existing products are red herrings to generate data that can create whole new products and business lines.[4] I liked this. It was something I could say. I could see the work of my talking being to share a useful conceptual flip. My friend Jesse Bettencourt helped formulate the idea and sent me this article about Google Maps as an example of how Google uses products and platform to generate new data. I sat down to read it one Saturday and footnote six caught my attention:
Footnote 6 in Justin O’Beirne’s excellent piece on Google Maps. The orange highlight indexes the modicum of doubt in my mind that, while I’ve told multiple people this was footnote 6, I may just well have been mistaken, but I was sure O’Beirne referenced Henry Ford, so I used that as my search term.
I loved the oddness of the detail. And the more I searched, the stranger it got. Thomas Edison helped Henry Ford started a charcoal production facility after he had too much wood from the byproduct of his car business? Kingsford charcoal was a spinoff, post acquisition by Clorox, of a company founded by Henry Ford? Henry Ford pulled one of those oblique marketing moves like the Michelin Brothers, using the charcoal businesses to advertise the wonderful picnics that waited at the end of a long car ride to give people somewhere to drive to?[5] It gripped me. Provided joy in telling it to others. I wanted people to know this. Gripped me enough that it became almost inevitable that I begin my talk with it. After all, I needed a particular story to ground what was otherwise an abstract idea. I go back and forth on my opinion of the Malcolm Gladwellian New Yorker article, which I (potentially erroneously, as I am not Gladwell expert) structure as:
Start with an anecdote that instantiates an abstract idea
Zoom out to articulate the abstraction
Show other examples of the abstraction
Potentially come back to unpack another aspect of the abstraction
Give a conclusion people can remember
This is more or less how my talk is structured. I would have loved to use a whole new form, pushing the genre of the talk to push the boundaries of how we communicate and truly lead to something new. All in due time.
Even after finding and getting excited about Henry Ford, I prevaricated. I wasn’t sure if the thesis was too analytical, wasn’t sure if I wanted to use these precious 12 minutes to show the world my heart, not my mind. There was a triumphant 40 or so hours where I was planning to tell the world’s most boring story from the annals of AI, a story about a team at a Big Four firm that builds a system to automate a review of the generally acceptable accounting principles (GAAP) checklist. I liked it because it’s moral was about teams working together. It showed that real progress with AI won’t be the headlines we read about, it will be the handwritten digit recognition systems that made the ATM possible, the natural language processing tools that made the swipe type on the Android possible. Humble tools we don’t know about but that impact us every day. This would have been a great talk. Aspects from it show up in many of my talks. Maybe some day I’ll give it.
In the end, I never actually wrote my TED talk. I told people I was memorizing an unwritten script. For me, the writing you read on this blog is a very different mode of being than the speaking I do in talks. The acts are separate. My mind space is separate. So, I gave up trying to write a talk and went back to my phrases, my chunks. Went back to rehearsing for an invisible audience. I walked 19 miles up the Hudson River on the day I gave my talk. I had my AirPods in and pretended I was talking on the phone so people didn’t think I was crazy. I suspect I needed the pretense to cushion my concentration in the first place. It was a gorgeous day. I took photos of ships and docks and branches and black struts and rainbow construction cones in bathroom entrances. I repeated sentences out loud again and again until I found their dormant lyricism. I practiced my concerto by myself. And then, I practiced in front of my boyfriend in the hotel room one last time before the show. He listened lovingly, patiently, supportively. He was proud. I felt comfortable having him watch me.
I pulled off the performance. Had a few hiccups here and there, but I made it. I reconnected with Teresa Bejan, a fellow speaker that evening and a former classmate from the University of Chicago. I did one dress rehearsal with my team at work and will always remember their keen attention and loving support. And I found a way to slide my values, my heart, into the talk, ending it with a phrase that encapsulates why I believe technology is and always will be a celebration of human creativity:
Machines did not see steaming coffee, grilled meats and toasted sandwiches in a pile of sawdust. Humans did. It’s when Ford collaborated with his teams that they were able to take the fruits of yesterday’s work and transform it into tomorrow’s value. And that’s what I see as the promise of artificial intelligence.
[1] In Two lessons from giving talks, I explained why having the AV break down two thirds of the way into a talk may be a hidden secret to effective communication. It breaks the fourth wall, engaging the audience’s attention because it breaks their minds’ expectation that they are in “listen to a talk” mode and engages their empathy. When this has happened to me, the sudden connection with the audience then fuels me to be louder and more creative. We imagine the missing slides together. We connect. It’s always been an incredibly positive feedback loop.
[2] Michael Jackson felt the need to “stress”, at the beginning of the Thriller music video, that “due to his strong personal convictions, [he wishes] to stress that [Thriller] in no way endorses a belief in the occult.” It’s worth pausing to ask how it’s possible that someone could mistake Thriller as a religious or cult-like ritual, not seeing the irony or camp. The gap between what you think you are saying and what ends up being hard never ceases to amaze me. It’s bewilderingly difficult to write an important email to a group of colleagues that communicates what you intend it to communicate, in particular when emotions and selective information flow and a plurality of goals and intentions kicks in. One of my first memories of appreciating that acutely was when people commented on a 5-minute pitch version of my dissertation I gave at the Stanford BiblioTech conference in 2012. One commenter took an opinion I intended to attribute to Blaise Pascal as something I endorsed at face value. I thought I was reporting on what someone else thought; the other heard it as something I thought. These performative nuances of meaning are crucial, and, I believe, a crucial leadership skill is to be able to manage them as a virtuosic novelist manages the symphony of voices and minds in the characters of her novel. This is one of the many reasons that we need to preserve and develop a rigorous humanistic education in the 21st century. The nuances of how humans make meaning together will be all the more valuable as machines take over more and more narrow skills tasks. Fortunately, the quantum entanglement of human egos will keep us safe for years to come. I’d like to resurrect programs like BiblioTech. They are critically important.
Side note 2. In May, 2005, an old Rasta, high as a kite, told me at the end of a hike through a mountain river near Ocho Rios that I looked like Michael Jackson, presumably towards the end of his life when his skin was more white. That was also a bizarre moment of viewing myself as others view me.
[3] Alex also told me about an XPRIZE for an AI-generated TED talk back in 2014. Also, my dear friend and forever colleague Dan Bressler came up with the same idea down the line and we had a little moratorium eulogizing a stillborn.
[4] Andrew Ng has shared similar ideas in many of his talks about building AI products, like this one.
[5] The Michelin restaurant guide, in my mind, predated the contemporary fad of selling experiences rather than products. Imagine how difficult it would be to market tires. A standard product marketing approach would quickly bore of describing ridges and high-quality rubber. But giving people awesome places to drive to is another story. I think it’s genius. Here’s a photo of an early guide.
The Michelin Brothers capitalized on the excitement of being able to try out restaurants that would have been too far to reach and on the desires to be part of the elite.
The featured image is of an unopened one-pound box of Ford Charcoal Briquets, dating back to 1935-37 and available for purchase on WorthPoint, The Internet of Stuff TM. Seller indicates that she does “not know if briquettes still burn as box has not been opened.” The briquettes were also son by the ton. Can you imagine a ton of charcoal? One of my favorite details, which made its way into my talk, is that a “modern picnic” back in the 1930s featured “sizzling broiled meats, steaming coffee, and toasted sandwiches.” The back of the box marketed more of the “hundred uses” of this “concentrated source of fuel”: to build a cheerful fire in the home (also useful for broiling steak and popping corn), to add a distinct flavor to broiled lobster and fish on boats and yachts without smoking up the place, to make tastier meats in restaurants that keep customers coming back. I find the particularity of the language a delightful contrast to the meaninglessness of the language we fill our brains with in the tech industry, peddling jargon that we kinda think refers to something but that we’re never quite sure refers to anything except the waves of a moment’s trend. Let’s change that.
The back of a box of Ford Charcoal Briquets, packaged between 1935-1937