
This week’s coverage of the Facebook and Cambridge Analytica debacle[1] (latest Guardian article) has brought privacy top of mind and raised multiple complex questions[2]:
Is informed consent nothing but a legal fiction in today’s age of data and machine learning, where “ongoing and extensive data collection can be neither fully informed nor truly consensual — especially since it is practically irrevocable?”
Is tacit consent-our silently agreeing to the fine print of privacy policies as we continue to use services-something we prefer to grant given the nuisance, time, and effort required to understand the nuances of data use? Is consent as a mechanism too reliant upon the supposition that privacy is an individual right and, therefore, available for an individual to exchange-in varying degrees-for the benefits and value from some service provider (i.e., Facebook likes satisfying our need to be both loved and lovely)? If consent is defunct, what legal structure should replace it?

How should we update outdated notions of what qualifies as personally identifiable information (PII), which already vary across different countries and cultures, to account for the fact contemporary data processing techniques can infer aspects of our personal identity from our online (and, increasingly, offline) behavior that feel more invasive and private than our name and address? Can more harm be done to an individual using her social security/insurance number than psychographic traits? In which contexts?
Would regulatory efforts to force large companies like Facebook to “lock down” data they have about users actually make things worse, solidifying their incumbent position in the market (as Ben Thompson and Mike Masnick argue)?
Is the best solution, as Cory Doctorow at the Electronic Frontier Foundation argues, to shift from having users (tacitly) consent to data use, based on trust and governed by the indirect forces of market demand (people will stop using your product if they stop trusting you) and moral norms, to building privacy settings in the fabric of the product, enabling users to engage more thoughtfully with tools?[3]
Many more qualified than I are working to inform clear opinions on what matters to help entrepreneurs, technologists, policymakers, and plain-old people[4] respond. As I grapple with this, I thought I’d share a brief and incomplete history of the thinking and concepts undergirding privacy. I’ll largely focus on the United States because it would be a book’s worth of material to write even brief histories of privacy in other cultures and contexts. I pick the United States not because I find it the most important or interesting, but because it happens to be what I know best. My inspiration to wax historical stems from a keynote I gave Friday about the history of artificial intelligence (AI)[5] for AI + Public Policy: Understanding the shift, hosted by the Brookfield Institute in Toronto.
As is the wont of this blog, the following ideas are far from exhaustive and polished. I offer them for your consideration and feedback.
The Fourth Amendment: Knock-and-Announce
As my friend Lisa Sotto eloquently described in a 2015 lecture at the University of Pennsylvania, the United States (U.S.) considers privacy as a consumer right, parsed across different business sectors, and the European Union (EU) considers privacy as a human right, with a broader and more holistic concept of what kinds of information qualify as sensitive. Indeed, one look at the different definitions of sensitive personal data in the U.S. and France in the DLA Piper Data Protection Laws of the World Handbook shows that the categories and taxonomies are operating at different levels. In the U.S., sensitive data is parsed by data type; in France, sensitive data is parsed by data feature:
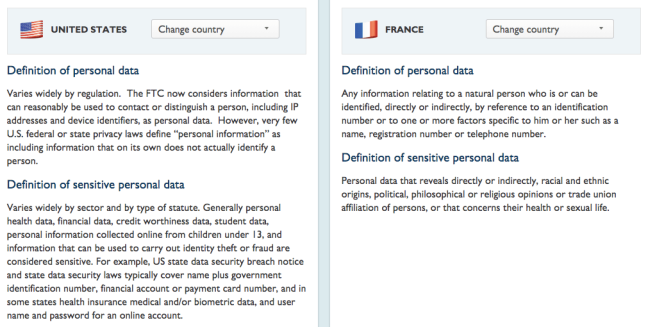
It seems potentially, possibly plausible (italics indicating I’m really unsure about this) that the U.S. concept of privacy as being fundamentally a consumer right dates back to the original elision of privacy and property in the Fourth Amendment to the U.S. Constitution:
The right of the people to be secure in their persons, houses, papers, and effects, against unreasonable searches and seizures, shall not be violated, and no Warrants shall issue, but upon probable cause, supported by Oath or affirmation, and particularly describing the place to be searched, and the persons or things to be seized.
We forget how tightly entwined protection of property was to early U.S. political theory. In his Leviathan, for example, seventeenth-century English philosopher Thomas Hobbes derives his theory of legitimate sovereign power (and the notion of the social contract that influenced founding fathers like Jefferson and Madison) from the need to provide individuals with some recourse against intrusions on their property; otherwise we risk devolving to the perpetually anxious and miserable state of the war of all against all, where anyone can come in and ransack our stuff at any time.
The Wikipedia page on the Fourth Amendment explains it as a countermeasure against general warrants and writs of assistance British colonial tax collectors were granted to “search the homes of colonists and seize ‘prohibited and uncustomed’ goods.” What matters for this brief history is the foundation that early privacy law protected people’s property-their physical homes-from searches, inspections, and other forms of intrusion or surveillance by the government.
Katz v. United States: Reasonable Expectations of Privacy
Over the past 50 years, new technologies have fracked the bedrock assumptions of the Fourth Amendment.[6] The case law is expansive and vastly exceeds the cursory overview I’ll provide in this post. Cindy Cohn from the Electronic Frontier Foundation has written extensively and lucidly on the subject.[7] As has Daniel Solove.
Perhaps the seminal case shaping contemporary U.S. privacy law is Katz v. United States, 389 U.S. 347 (1967). A 2008 presentation from Artemus Ward at Northern Illinois University presents the facts and a summary of the Supreme Court Justices’ opinions in these three slides (there are also dissenting opinions):



There are two key questions here:
- Does the right to privacy extend to telephone booths and other public places?
- Is a physical intrusion necessary to constitute a search?
Justice Harlan’s comments regarding the “actual (subjective) expectation of privacy” that society is prepared to recognize as “reasonable” marked a conceptual shift to pave the way for the Fourth Amendment to make sense in the digital age. Katz shifted the locus of constitutional protections against unwarranted government surveillance from one’s private home-property that one owns-to public places that social norms recognize as private in practice if not name (a few cases preceding Katz paved the way for this judgment).
This is watershed: when any public space can be interpreted as private in the eyes of the beholder, the locus of privacy shifts from an easy-to-agree-upon-objective-space like someone’s home, doors locked and shades shut, to a hard-to-agree-upon-subjective-mindset like someone’s expectation of what should be private, even if it’s out in a completely public space, just as long as those expectations aren’t crazy (i.e., that annoying lady somehow expecting that no one is listening to her uber-personal conversation about the bad sex she had with the new guy from Tinder as she stands in a crowded checkout line waiting to purchase her chia seed concoction and her gluten-free crackers[8]) but accord with the social norms and practices of a given moment and generation.
Imagine how thorny it becomes to decide what qualifies as a reasonable expectation for privacy when we shift from a public phone booth occupied by one person who can shut the door (as in Katz) to:
- internet service providers shuffling billions of text messages, phone calls, and emails between individuals, where (perhaps?) the standard expectation is that when we go through the trouble of protecting information with a password (or two-factor authentication), we’re branding these communications as private, not to be read by the government or the private company providing us with the service (and metadata?);
- GPS devices placed on the bottom of vehicles, as in United States v. Jones, 132 S.Ct. 945 (2012), which in themselves may not seem like something everyone has to worry about often but which, given the category of data they generate, are similar to any and all information about how we transact and move in the world, revealing not just what our name is but which coffee shops and doctors (or lovers or political co-conspirators) we visit on a regular basis, prompting Justice Sandra Sotomayor to be very careful in her judgments;
- social media platforms like Facebook, pseudo-public in nature, that now collect and analyze not only structured data on our likes and dislikes, but, thanks to advancing AI capabilities, image, video, text, and speech data;
- etc.
Just as Zeynep Tufecki argues that informed consent loses its power in an age where most users of internet services and products don’t rigorously understand what use of their data they’re consenting too, so too does Cohn believe that the “‘reasonable expectation of privacy’ test currently employed in Fourth Amendment jurisprudence is a poor test for the digital age.”[9] As with any shift from criticism to pragmatic solutions, however, the devil is in the details. If we eliminate a reasonableness test because it’s too flimsy for the digital age, what do we replace it to achieve the desired outcomes of protecting individual rights to free speech and preventing governmental overreach? Do we find a way to measure actual harm suffered by an individual? Or should we, as Lex Gill suggested Friday, somehow think about privacy as a public good rather than an individual choice requiring individual consent? What are the different harms we need to guard against in different contexts, given that use of data for targeted marketing has different ramifications than government wiretapping?
These questions are tricky to parse because, in an age where so many aspects of our lives are digital, privacy bleeds into and across different contexts of social, political, commercial, and individual activity. As Helen Nissenbaum has masterfully shown, our subjective experience of what’s appropriate in different social contexts influences our reasonable expectations of privacy in digital contexts. We don’t share all the intimate details of our personal life with colleagues in the same way we do with close friends or doctors bound by duties of confidentiality. Add to that that certain social contexts demand frivolity (that ironic self you fashion on Facebook) and others, like politics, invite a more aspirational self.[10] Nissenbaum’s theory of contextual integrity, where privacy is preserved when information flows respect the implicit, socially-constructed boundaries that graft the many sub-identities we perform and inhabit as individuals, applies well to Cambridge Analytica debacle. People are less concerned by private companies using social media data for psychographic targeting than they are for political targeting; the algorithms driving stickiness on site and hyper-personalized advertising aren’t fit to promote the omnivorous, balanced information diet required to understand different sides of arguments in a functioning democracy. Being at once watering hole to chat with friends, media company to support advertising, and platform for political persuasion, Facebook collapses distinct social spheres into one digital platform (which also complicates anti-trust arguments, as evident in this excellent Intelligence Squared debate).
A New New Deal on Data: Privacy in the Age of Machine Learning
In 2009, Alex “Sandy” Pentland of the MIT Media Lab began the final section of his article calling for a “new deal” on data as follows:
Perhaps the greatest challenge posed by this new ability to sense the pulse of humanity is creating a “new deal” around questions of privacy and data ownership. Many of the network data that are available today are freely offered because the entities that control the data have difficulty extracting value from them. As we develop new analytical methods, however, this will change.[11]
This ability to “sense the pulse of humanity,” writes Pentland earlier in the article, arises from the new data generation, collection, and processing tools that have effectively given the human race “the beginnings of a working nervous system.” Pentland contrasts what we are able to know about people’s behavior today-where we move in the world, how many times our hearts beat per minute, whom we love, whom we are attracted to, what movies we watch and when, what books we read and stop reading in between, etc-with the “single-shot, self-report data” data, e.g., yearly censuses, public polls, and focus groups, that characterized demographic statistics in the recent past. Note that back in 2009, the hey day of the big data (i.e., collecting and storing data) era, Pentland commented that while a ton of data was collected, companies had difficulty extracting value. It was just a lot of noise backed by the promise of analytic potential.
This has changed.
Machine learning has unlocked the potential and risks of the massive amounts of data collected about people.
The standard risk assessment tools (like privacy impact assessments) used by the privacy community today focus on protecting the use of particular types of data, PII like proper names and e-mail addresses. There is a whole industry and tool kit devoted to de-identification and anonymization, automatically removing PII while preserving other behavioral information for statistical insights. The problem is that this PII-centric approach to privacy misses the boat in the machine learning age. Indeed, what Cambridge Analytica brought to the fore was the ability to use machine learning to probabilistically infer not proper names but features and types from behavior: you don’t need to check a gender box for the system to make a reasonably confident guess that you are a woman based on the pictures you post and the words you use; private data from conversations with your psychiatrist need not be leaked for the system to peg you as neurotic. Deep learning is so powerful because it is able to tease out and represent hierarchical, complex aspects of data that aren’t readily and effectively simplified down variables we can keep track of and proportionately weight in our heads: these algorithms can, therefore, tease meaning out of a series of actions in time. This may not peg you as you, but it can peg you as one of a few whose behavior can be impacted using a given technique to achieve a desired outcome.
Three things have shifted:
- using machine learning, we can probabilistically construct meaningful units that tell us something about people without standard PII identifiers;
- because we can use machine learning, the value of data shifts from the individual to statistical insights across a distribution; and
- breaches of privacy that occur at the statistical layer instead of the individual data layer require new kinds of privacy protections and guarantees.
The technical solution to this last bullet point is a technique called differential privacy. Still in the early stages of commercial adoption,[12] differential privacy thinks about privacy as the extent to which individual data impacts the shape of some statistical distribution. If what we care about is the insight, not the person, then let’s make it so we can’t reverse engineer how one individual contributed to that insight. In other words, the task is to modify a database such that:
if you have two otherwise identical databases, one with your information and one without it, the probability that a statistical query will produce a given result is (nearly) the same whether it’s conducted on the first or second database.
Here’s an example Matthew Green from Johns Hopkins gives to help develop an intuition for how this works:
Imagine that you choose to enable a reporting feature on your iPhone that tells Apple if you like to use the 💩 emoji routinely in your iMessage conversations. This report consists of a single bit of information: 1 indicates you like 💩 , and 0 doesn’t. Apple might receive these reports and fill them into a huge database. At the end of the day, it wants to be able to derive a count of the users who like this particular emoji.
It goes without saying that the simple process of “tallying up the results” and releasing them does not satisfy the DP definition, since computing a sum on the database that contains your information will potentially produce a different result from computing the sum on a database without it. Thus, even though these sums may not seem to leak much information, they reveal at least a little bit about you. A key observation of the differential privacy research is that in many cases, DP can be achieved if the tallying party is willing to add random noise to the result. For example, rather than simply reporting the sum, the tallying party can inject noise from a Laplace or gaussian distribution, producing a result that’s not quite exact — but that masks the contents of any given row.
This is pretty technical. It takes time to understand it, in particular if you’re not steeped in statistics day in and day out, viewing the world as a set of dynamic probability distributions. But it poses a big philosophical question in the context of this post.
In the final chapters of Homo Deus, Yuval Noah Harari proposes that we are moving from the age of Humanism (where meaning emanates from the perspective of the individual human subject) to the age of Dataism (where we question our subjective viewpoints given our proven predilections for mistakes and bias to instead relegate judgment, authority, and agency to algorithms that know us better than we know ourselves). Reasonable expectations for privacy, as Justice Harlan indicated, are subjective, even if they must be supported by some measurement of norms to qualify as reasonable. Consent is individual and subjective, and results in principles like that of minimum use for an acknowledged purpose because we have limited ability to see beyond ourselves, we create traffic jams because we’re so damned focus on the next step, the proxy, as opposed to viewing the system as a whole from a wider vantage point, and only rarely (I presume?) self-identify and view ourselves under the round curves of a distribution. So, if techniques like differential privacy are better apt to protect us in an age where distributions matter more than data points, how should we construct consent, and how should we shape expectations, to craft the right balance between the liberal values we’ve inherited and this mathematical world we’re building? Or, do we somehow need to reformulate our values to align with Dataism?
And, perhaps most importantly, what should peaceful resistance look like and what goals should it achieve?
[1] What one decides to call the event reveals a lot about how one interprets it. Is it a breach? A scandal? If so, which actor exhibits scandalous behavior: Nix for his willingness to profit from the manipulation of people’s psychology to support the election of an administration that is toppling democracy? Zuckerberg for waiting so long to acknowledge that his social media empire is more than just an advertising platform and has critical impacts on politics and society? The Facebook product managers and security team for lacking any real enforcement mechanisms to audit and verify compliance with data policies? We the people, who have lost our ability and even desire to read critically, as we prefer the sensationalism of click bait, goading technocrats to optimize for whatever headline keeps us hooked to our feed, ever curious for more? Our higher education system, which, falling to economic pressures that date back to (before but were aggravated by) the 2008-2009 financial crisis are cutting any and all curricula for which it’s hard to find a direct, casual line to steady and lucrative employment, as our education system evolves from educating a few thoughtful priests to educating many industrial workers to educating engineers who can build stuff and optimize everything and define proxies and identify efficiencies so we can go faster, faster until we step back and take the time to realize the things we are building may not actually align with our values, that, perhaps, we may need to retain and reclaim our capacities to reflect and judge and reason if we want to sustain the political order we’ve inherited? Or perhaps all of this is just the symptom of much larger, complex trend in World History that we’re unable to perceive, that the Greeks were right in thinking that forms of government pass through inevitable cycles with the regularity of the earth rotating around the sun (an historical perspective itself, as the Greeks thought the inverse) and we should throw our hands up like happy nihilists, bowing down to the unstoppable systemic forces of class warfare, the give and take between the haves and the have nots, little amino acids ever unable to perceive how we impact the function of proteins and how they impact us in return?
And yet, it feels like there may be nothing more important than to understand this and to do what little-what big-we can to make the world a better place. This is our dignity, quixotic though it may be.

[2] One aspect of the fiasco* I won’t write about but that merits at least passing mention is Elon Musk’s becoming the mascot for the #DeleteFacebook movement (too strong a word?). The New York Times coverage of Musk’s move references Musk and Zuckerberg’s contrasting opinions on the risks AI might pose to humanity. From what I understand, as executives, they both operate on extremely long time scales (i.e., 100 years in the future), projecting way out into speculative futures and working backwards to decide what small steps man should take today to enable Man to take giant future leaps (gender certainly intended, especially in Musk’s case, as I find his aesthetic and many of the very muscular men I’ve met from Tesla at conferences is not dissimilar from the nationalistic masculinity performed by Vladimir Putin). Musk rebuffed Zuckerberg’s criticism that Musk’s rhetoric about the existential threat AI poses to humanity is “irresponsible” by saying that Zuckerberg’s “understanding of the subject is limited.” I had some cognitive dissonance reading this, as I presumed the risk Musk was referring to was that of super-intelligence run amok (à la Nick Bostrom, whom I admittedly reference as a straw man) rather than that of our having created an infrastructure that exacerbates short-term, emotional responses to stimuli and thereby threatens the information exchange required for democracy to function (see Alexis de Tocqueville on the importance of newspapers in Democracy in America). My takeaway from all of this is that there are so many different sub-issues all wrapped up together, and that we in the technology community really do need to work as hard as we can to references specifics rather than allow for the semantic slippage that leaves interpretation in the mind of the beholder. It’s SO HARD to do this, especially for pubic figures like Musk, given that people’s attention spans are limited and we like punchy quotables at a very high level. The devil is always in the details.
[3] Doctorow references Laurence Lessig’s Code and Other Laws of Cyberspace, which I have yet to read but is hailed as a classic text on the relationship between law and code, where norms get baked into our technologies in the choices of how we write code.
[4] I always got a kick out of the song Human by the Killers, whose lyrics seem to imply a mutually exclusive distinction between human and dancer. Does the animal kingdom offer better paradigms for dancers than us poor humans? Must depend on whether you’re a white dude.
[5] My talk drew largely from Chris Dixon‘s extraordinary Atlantic article How Aristotle Created the Computer. Extraordinary because he deftly encapsulates 2000 years of the history of logic into a compelling, easy-to-read article that truly helps the reader develop intuitions about deterministic computer programs and the shift to a more inductive machine learning paradigm, while also not leaving the reader with the bitter taste of having read an overly general dilettante. Here’s one of my slides, which represents how important it was for the history of computation to visualize and interpret Aristotelian syllogisms as sets (sets lead to algebra lead to encoding in logical gates lead to algorithms).

Fortunately (well, we put effort in to coordinate), my talk was a nice primer for Graham Taylor‘s superbly clear introduction to various forms of machine learning. I most liked his section on representation learning, where he showed how the choice of representation of data has an enormous impact on the performance of algorithms:
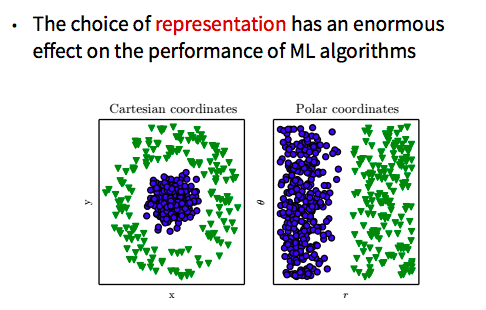
[6] If you’re interested in contemporary Constitutional Law, I highly recommend Roman Mars’s What Trump Can Teach us about Con Law podcast. Mars and Elizabeth Joh, a law school professor at UC Davis, use Trump’s entirely anomalous behavior as catalyst to explore various aspects of the Constitution. I particularly enjoyed the episode about the emoluments clause, which prohibits acceptance of diplomatic gifts to the President, Vice President, Secretary of State, and their spouses. The Protocol Gift Unit keeps public record of all gifts presidents did accept, including justification of why they made the exception. For example, in 2016, former President Obama accepted Courage, an olive green with black flecks soapstone sculpture, depicting the profile of an eagle with half of an indigenous man’s face in the center, valued at $650.00, from His Excellency Justin Trudeau, P.C., M.P., Prime Minister of Canada, because “non-acceptance would cause embarrassment to donor and U.S. Government.”

[7] Cindy will be in Toronto for RightsCon May 16-18. I cannot recommend her highly enough. Every time I hear her speak, every time I read her writing, I am floored by her eloquence, precision, and passionate commitment to justice.
[8] Another thing I cannot recommend highly enoug is David Foster Wallace’s commencement speech This is Water. It’s ruthlessly important. It’s tragic to think about the fact that this human, this wonderfully enlightened heart, felt the only appropriate act left was to commit suicide.
[9] A related issue I won’t go into in this post is the third-party doctrine, “under which an individual who voluntarily provides information to a third party loses any reasonable expectation of privacy in that information.” (Cohn)
[10] Eli Pariser does a great job showing the difference between our frivolous and aspiration selves, and the impact this has on filter bubbles, in his 2011 quite prescient monograph.
[11] See also this 2014 Harvard Business Review interview with Pentland. My friend Dazza Greenwood first introduced me to Pentland’s work by presenting the blockchain as an effective means to executive the new deal on data, empowering individuals to keep better track of where data flow and sit, and how they are being used.
[12] Cynthia Dwork’s pioneering work on differential privacy at Microsoft Research dates back to 2006. It’s currently in use at Apple, Facebook, and Google (the most exciting application being fused with federated learning across the network of Android users, to support localized, distributed personalization without requiring that everyone share their digital self with Google’s central servers). Even Uber has released an open-source differential privacy toolset. There are still many limitations to applying these techniques in practice given their impact on model performance and the lack of robust guarantees on certain machine learning models. I don’t know of many instances of startups using the technology yet outside a proud few in the Georgian Partners portfolio, including integrate.ai (where I work) and Bluecore in New York City.
The featured image is from an article in The Daily Dot (which I’ve never heard of) about the Mojave Phone Booth, which, as Roman Mars delightfully narrates in 99% Invisible became a sensation when Godfrey “Doc” Daniels (trust me that link is worth clicking on!!) used the internet to catalogue his quest to find the phone booth working merely from its number: 760-733-9969. The tattered decrepitude of the phone booth, pitched against the indigo of the sunset, is a compelling illustration of the inevitable retrograde character of common law precedent. The opinions in Katz v. United States regarded reasonably expectations for privacy were given at a time when digital communications occurred largely over the phone: is it even possible for us to draw analogies between what privacy meant then and what it could mean now in the age of centralized platform technologies whose foundations are built upon creating user bases and markets to then exchange this data for commercial and political advertising purposes? But, what can we use to anchor ethics and lawful behavior if not the precedent of the past, aligned against a set of larger, overarching principles in an urtext like the constitution, or, in the Islamic tradition, the Qur’an?

So timely, and you’ve given me far too many ideas for interesting reads with which to follow up. Thanks for that.
LikeLiked by 1 person
Very glad to hear that. So much to think about!
LikeLike
1) This is awesome and the number of interesting links in here is stupid
2) Minor point - you seem to imply that deep learning is essential to companies’ abilities to infer new information (might be misreading this). I don’t think that’s true - for instance, the original Kosinski paper that kicked off the whole Cambridge Analytica thing uses logistic regression, which is basically Stats 101. I’d say the technological innovation at play is more the ability to collect unthinkable amounts/types of data, rather than improvements in statistical tools of analysis
LikeLike
On 1), thanks!
On 2), I can see why you left with that impression. Didn’t mean to imply it, but did mean to imply that there is a difference between deterministic identity (Kathryn Hume is a proper name that refers to this one individual) and probabilisitic identity (this collection of features leads us to infer with 95% probability that this person is a woman who reads too much philosophy and writes long blog posts, and thereby must be neurotic), and that probabilistically-constructed identities pose different privacy risks than the existing frameworks are designed to protect.
LikeLiked by 1 person
Very interesting. So much to follow up on. Look forward to hearing your insights on footnote about handing over info to a third party and whether one’s expectation of privacy is then “unreasonable.” This hole in the law seems to me like the one in the dike that the boy stuck his finger into. Im interested to know more about its metamorphosis over time.
LikeLike